
We at Datavolo like to drink our own champagne, building internal tooling and operational workflows on top of the Datavolo Runtime, our distribution of Apache NiFi. We’ve written about several of these services, including our observability pipeline and Slack chatbots.
Of course, things don’t always go as planned in production environments, and that’s okay. Here, we dive into one example of how we used tooling provided within the Datavolo Runtime to troubleshoot some odd behavior from our FlowGen service.
What is FlowGen?
First of all, what is FlowGen? A service that translates natural language into ready-to-deploy data pipelines. I like to think of it as the easiest way to build data flows in Datavolo that would have saved me hundreds of hours if I had it 8 years ago. My colleague Mark described it better, so check out his blog post for more details and a great video demonstration.
Today, a free, pilot version of FlowGen is available as an enthusiastic bot in our Datavolo Community Slack Workspace. Data engineers and flow designers tag the @FlowGen user in the #ai-flow-generator channel and describe what they want to do. FlowGen quickly accepts the request, and lets them know that it’s working on it. Then, within a minute, they receive a response with a downloadable JSON file that can be uploaded into a Datavolo Runtime.
Datavolo Community members have used FlowGen to push database records into S3 buckets, securely transfer files from GCS into Splunk, and transform all sorts of complex JSON objects with ease.
What happened with FlowGen?
Unfortunately, FlowGen didn’t follow the “happy path” a few weeks ago when a user asked for a flow that ran an hourly data analysis through SQL queries. They did receive a flow to download after 45 seconds, but FlowGen’s first response acknowledging the message was a blob of JSON text that looked more like an echo of their Slack message metadata.
So, how did we figure out what happened and what needed to be fixed? First, we knew that the Datavolo Runtime was, in fact, running, since it sent back a flow definition. We had not received any alerts from our operational monitors or third-party status page subscriptions, so it was time to dig into the Datavolo Runtime itself.
Using the Datavolo Runtime UI, we navigated to the process group that hosts FlowGen. There were no errors or files stuck in queues. The drag-and-drop UI made it clear that FlowGen is set up as a set of serial processors to:
- Receive the Slack message with the ConsumeSlack processor
- Generate a quick response from OpenAI using Datavolo’s PromptChatGPT processor
- Send that quick response as a thread in Slack through the PublishSlack processor
- Continue processing the request through a RAG workflow that calls ChatGPT again
- Send the flow definition file back in a Slack thread, again through PublishSlack
There were no errors, so we identified and eliminated some possibilities. Did the LLM hallucinate? Was it a problem with Slack? A problem with the message that we sent to the PublishSlack processor? The next place to look was Data Provenance.
Data Provenance
Within the Datavolo Runtime, Data Provenance provides a persistent log of when and how each piece of data in the pipeline was created, dropped, modified, duplicated, etc. Built-in as a core part of the framework, Data Provenance provides the full history of changes through your entire data flow. This is especially useful both for security audits and for operational investigations, whether you’re looking at all of the changes for a single piece of data or all of the data changed by a single processor.
In this case, Data Provenance on the PromptChatGPT processor pointed clearly at the answer:
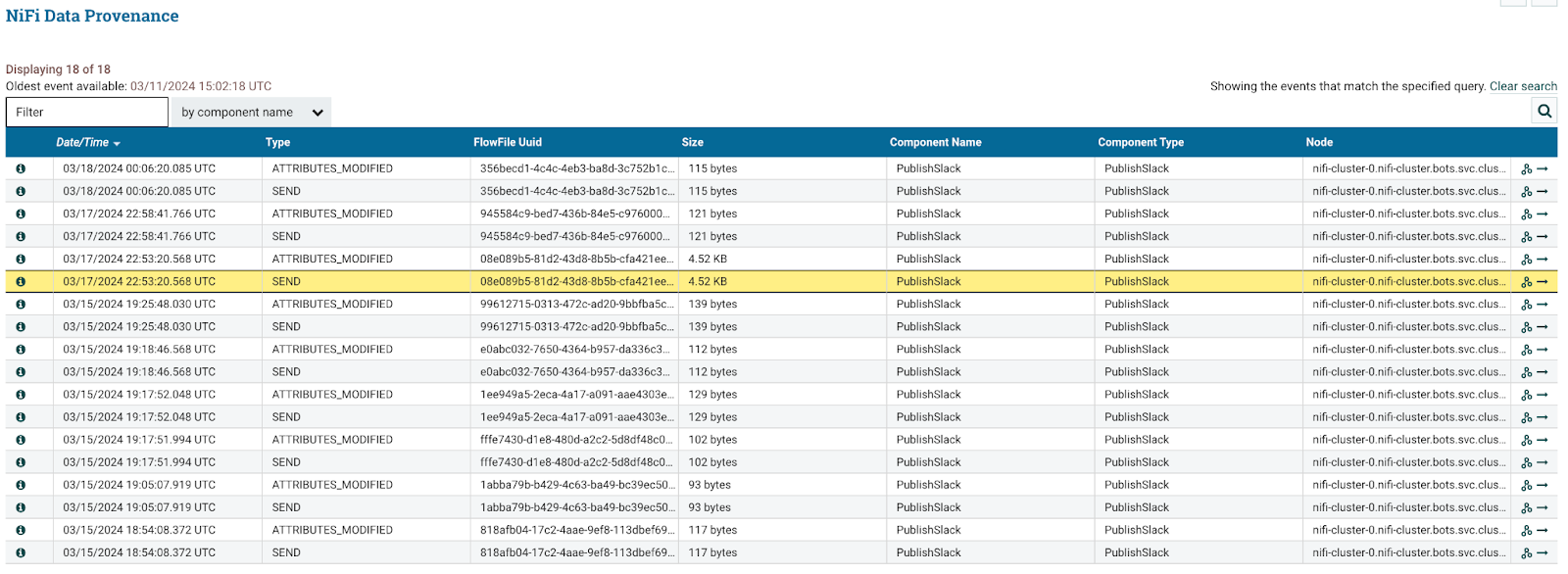
Every other message that we sent to Slack was around 100 bytes, but the problematic message sent at this time was 4.52 KB. So, we were reasonably sure that Slack was fine. Next, we looked upstream at data provenance for the PromptChatGPT processor that generated the Slack message.
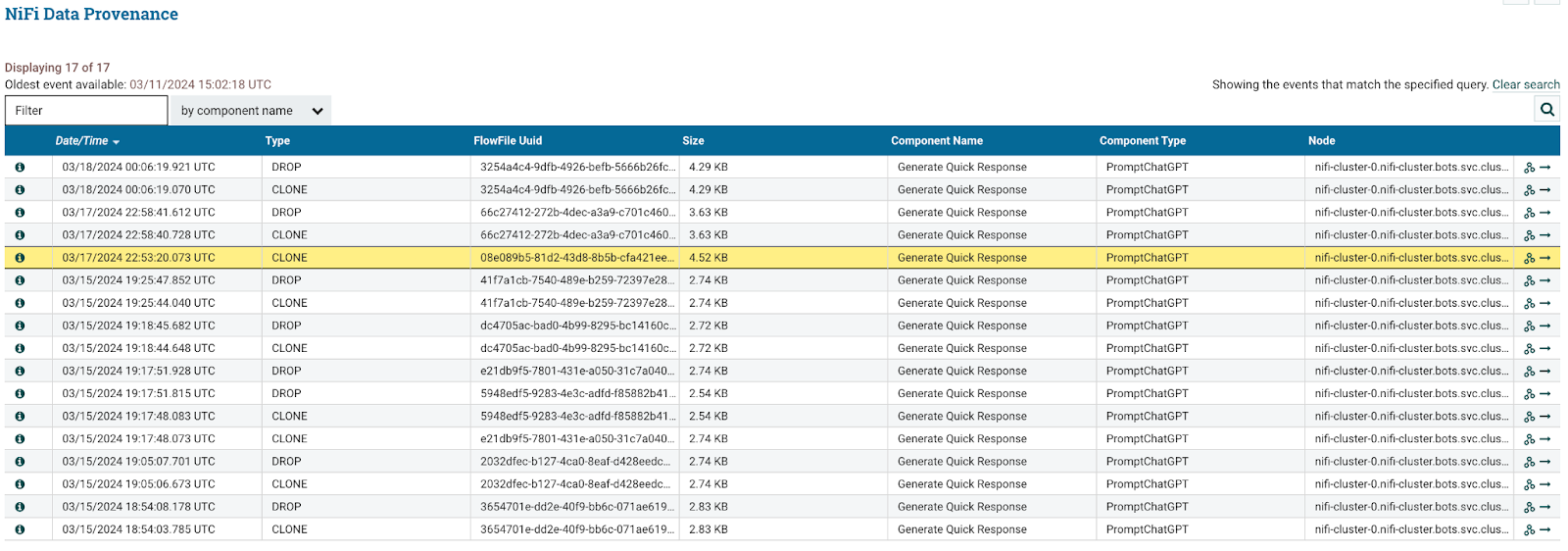
Without knowing the details of how PromptChatGPT works, we first noticed that this provenance entry was different from the rest. Instead of a CLONE operation followed by a DROP, there was only one CLONE that matched the 4.52 KB size of the message that went to Slack.
Runtime Logs
So, it seemed clear that something unusual happened in PromptChatGPT. We had an exact timestamp from the provenance event, but little more information about why the processor behaved this way. Using that timestamp, we inspected our Runtime logs for the minutes leading up to the anomaly.
Logs pointed directly to 3 attempts to invoke the OpenAI API for ChatGPT, all of which failed with 503 Unavailable responses. After 3 failed attempts, the processor stopped retrying. At this point, it routed the message to the “failure” output. Everything worked exactly as expected! However, as a relatively new addition in Datavolo’s operational flow, the “failure” route was incorrectly connected to the same downstream PublishSlack processor as the “success” route. Hence, the original JSON message from Slack went right back into the Slack thread.
Continuous Improvement
At this point, we knew “what” happened (data provenance) and “why” it happened (logs). That was enough information to improve the flow’s error handling within seconds. Instead of failing the entire pipeline, Datavolo’s platform makes it easy to handle errors at every step in the flow. You get the choice to retry, ignore, or route them to other handlers. In this case, we chose to skip / route around the quick reply flow to prevent any immediate issues from recurring, but we can change that again with a few simple clicks.
This was an especially interesting scenario because of the serial nature of the data pipeline supporting FlowGen. ChatGPT was unavailable during our first step calling it, but it was back online within a few seconds for the fourth step’s RAG pipeline to successfully process the request.
Data pipelines can be hard and risky if you’re building custom components to call new and evolving services. At Datavolo, we’re battle testing all of our components and flows not only through automation, but also by using them ourselves. Every Datavolo Runtime is purpose-built for AI data engineers, backed by the knowledge and experience of a team from the origins of Apache NiFi.
When you do need to bring your own code to the mix, rest assured that Datavolo Runtimes give you all these tools and more to deliver robust, scalable, and secure data pipelines.