
The Vectara and Datavolo integration and partnership
When building GenAI apps that are meant to give users rich answers to complex questions or act as an AI assistant (chatbot), we often use Retrieval Augmented Generation (RAG) and want to ground the responses on multiple sources of knowledge that we can continuously keep updated with recent, contextual information. This is a powerful architectural pattern, especially when it is made easy and accessible to developers. That’s just what Datavolo and Vectara have set out to do.
At Datavolo, we get a lot of great questions from the Apache NiFi community and we’re always eager to help users out. Since we’ve been fascinated by learning about making LLMs better with in-context patterns like RAG, we decided this would be a great opportunity to drink our own champagne and build a chatbot with multiple sources of knowledge using Datavolo and Vectara to help answer these questions. We felt this could increase user satisfaction within our community by providing automated ways of getting fast answers, and this could also give our engineers some time back to keep building compelling new features in the platform.
In this blog post, we demonstrate how to capture, transform, and index two important sources: technical docs that live in Google Drive and a stream of ongoing Slack conversations that contain previously answered questions and insights. We will show how to build a Datavolo data flow that captures and transforms documents and conversations before indexing them into Vectara.
Vectara is a RAG platform for embedding generative AI functionality into applications, chatbots, and products. Providing extraordinary results that are grounded on the user-provided data, Vectara’s serverless platform solves critical problems required for enterprise adoption, such as explainability, provenance, enforcement of access control, real-time updatability of contextual knowledge, and more.
Datavolo and Vectara are complementary tools within the AI stack that teams can use together to build powerful GenAI apps. As you’ll see in the technical walkthrough, Datavolo handles the data acquisition and preprocessing, using a visual development experience, while Vectara simplifies the RAG and ML pipeline needed for users to get the right insights from these sources of knowledge. A unique feature of Vectara is its use of metadata and custom dimensions, which gives users a powerful way to tune their search results with precision. Datavolo, with its transformation and enrichment capabilities, is the perfect fit for generating these metadata attributes.
Intro to Datavolo, powered by Apache NiFi
Built from the ground up to support the ETL pattern, Datavolo leverages a robust set of out-of-the-box processors to extract, clean, transform, enrich, and publish both unstructured and structured data. Datavolo is powered by Apache NiFi and is designed for continuous, event-driven ingest that can scale up on demand to cope with bursts of high-volume data.
Datavolo makes the job of the data engineer far easier due to some core design principles. Let’s define a few foundational abstractions in Datavolo and Apache NiFi so that we can better explain these design principles. Please find more details in the NiFi User Guide and in-depth Guide.
- FlowFiles are at the heart of Datavolo and its flow-based design. The FlowFile represents a single piece of data in Datavolo. A FlowFile is made up of two components: attributes (metadata made up of key/value pairs) and content (the payload).
- Processors are components in Datavolo that act on the data, from sourcing the data, to transforming it, and delivering it to end systems.
- A Dataflow is a directed graph of Processors (the nodes of the graph) connected by Relationships (the edges of the graph) through which FlowFiles flow in a continuous, event-driven manner.
Datavolo is built on the Apache NiFi project, but takes a giant leap forward in the data engineering domain by bringing several exciting new features to the table. These include:
- A managed cloud-native architecture that will make it easier to operate, scale, and secure data flows. With Datavolo, engineers can start building flows in minutes.
- Dozens of AI-specific capabilities for building LLM apps, including new processors and Datavolo-specific APIs to support advanced RAG patterns, integrations with embedding models, vector databases, and foundational LLMs.
- Datavolo will also be imbuing the data engineering experience with AI, including capabilities to create, understand, and manipulate scripted transforms as well as entire data flows using natural language
By building on top of Apache NiFi, Datavolo provides users a seamless workflow that scales with the data:
- The UI is not only the dataflow designer but it also instantiates and represents the live data pipeline itself, with no code to deploy. You can think of this as “UI-as-infrastructure” or an analogy we like is “Jenkins is to Airflow as Kubernetes is to Datavolo”, due to the declarative nature of Datavolo pipelines.
- For processors that integrate with external sources, targets, and APIs, Datavolo maintains the integrations as APIs change and new versions are released. Processors themselves are versioned for backwards compatibility.
- Datavolo makes it easy to interactively update pipelines on-the-fly, as well as to replay previous data. Users of Jupyter notebooks will find NiFi’s ability to instantly apply and review updates familiar and refreshing.
- Datavolo provides a secure and compliant infrastructure with a robust provenance system built in. Security, auditing, and data tracking is built into the foundation of NiFi rather than being tacked on.
Returning to the use case at hand, while the Datavolo documentation is comprehensive, there are always real world complexities that cannot be covered by just static docs. A lot of these experiences, issues, and solutions are captured in community conversations that happen within messaging platforms like Slack. To leverage these additional knowledge sources, we will combine the docs with a stream of ongoing Slack conversations that contain previously answered questions and insights and index both sources into Vectara. This will greatly enhance users’ search results in the Vectara app!
We’ll next discuss how the joint Datavolo and Vectara solution supports this use case and how we built the data pipeline.
To make it easier to incorporate Vectara into NiFi Dataflows, Datavolo has created two new processors for this integration, PutVectaraDocument and PutVectaraFile. With the PutVectaraDocument processor, which is designed for handling document chunks, it is simple to specify which parts of the FlowFile should be treated as text to be indexed within Vectara and which should be treated as metadata. This simple, yet powerful, integration shows just how powerful the Datavolo+Vectara combination is to drive high velocity solution development using visual tools.
The Challenge
We approach this as two separate data flows that load into the same Vectara corpus. First, we tackled processing Slack conversations as described in a recent blog on our website by developer Mark Payne.
In particular, we need the ability to stitch together adjacent Slack messages in order to index the messages into Vectara with the relevant contextual meaning. To do this, we first push the messages to a Postgres database. Then, for each message, we query the database to enrich the message. If the message is in a thread, we grab the 4 messages prior in the same thread, as well as the first message in the thread, which typically acts as a “title” for the conversation. For messages that are not part of a thread, we grab several prior messages in the same channel that are not threaded.
The Solution
For the Vectara integration, we used the same design approach as explained in that blog to pre-process the Slack messages before loading into Vectara. This illustrates the modularity and flexibility of Datavolo where one data flow can be used for many use cases. For this use case we processed the Slack messages as illustrated here:
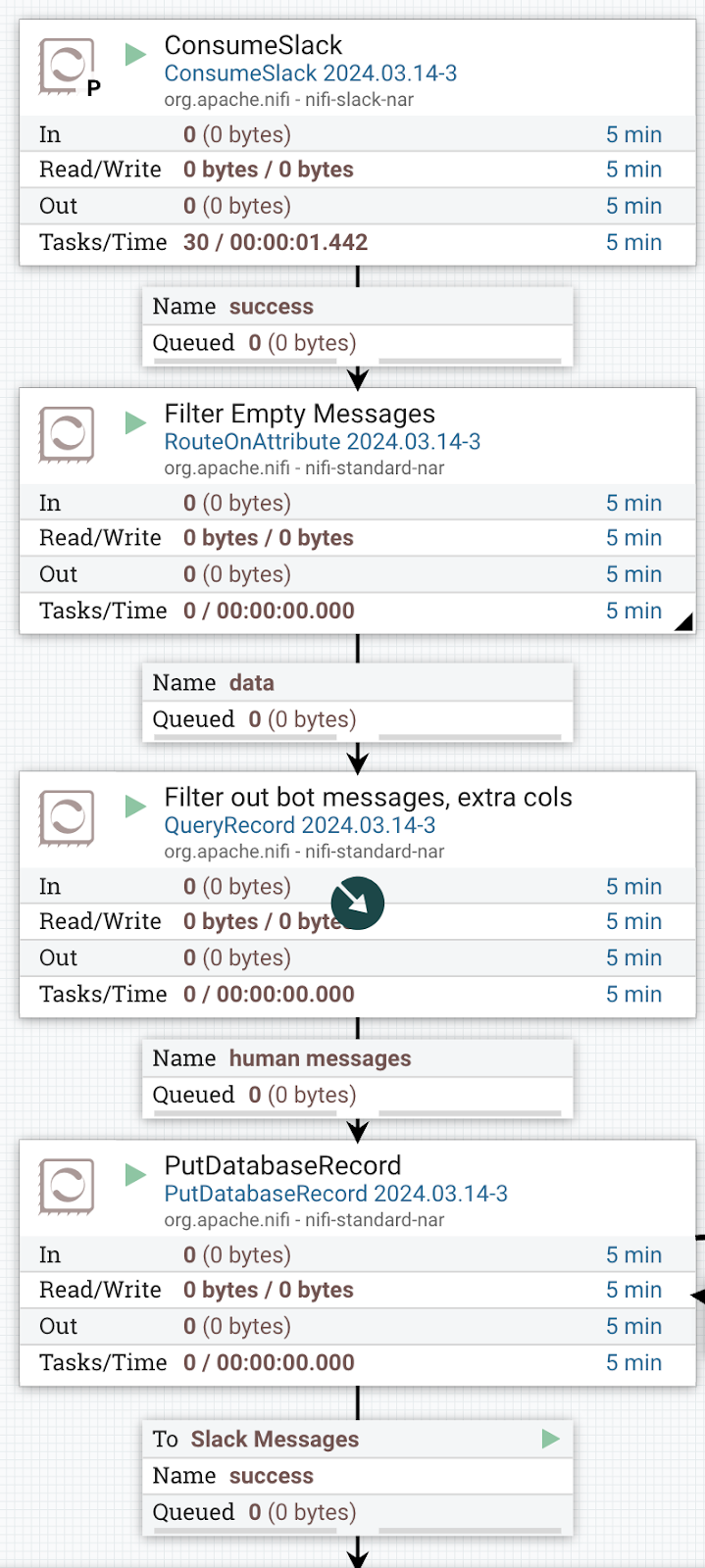 | 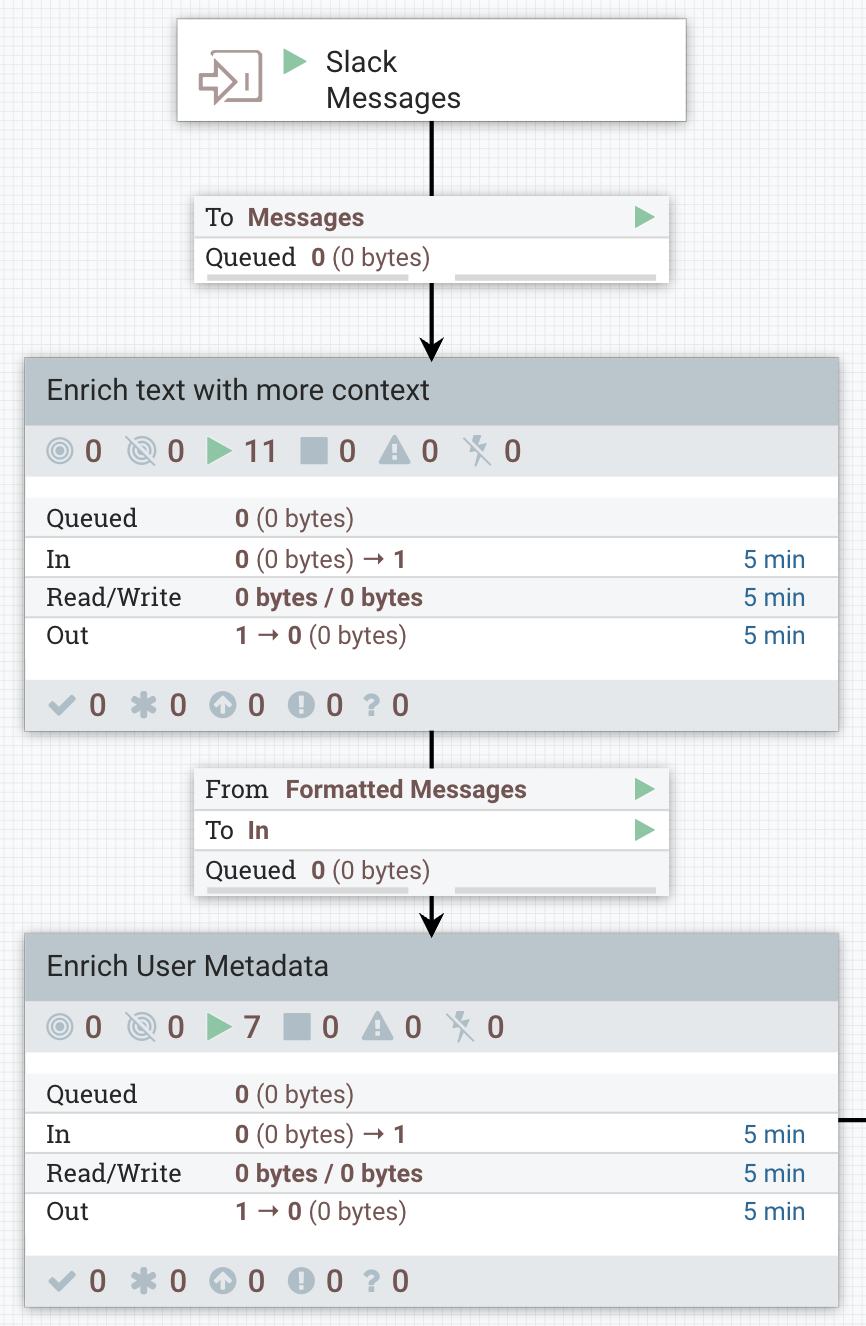 |
From this point we forked the data flow to further enrich the Slack messages with additional metadata needed for Vectara. We then proceeded to loading the content:
Metadata Attributes
Metadata attributes are fields that you want to tag the data with so that you can reference those fields while processing the retrieved results later on. For example, adding a “url” metadata attribute lets you enrich the results in the UI making each search result clickable. Also, the metadata attributes can be referenced in the LLM prompt to customize the output. In our data flow, we configure create_datetime as an additional metadata attribute for display in the Vectara app.
Filter Attributes
Unlike metadata attributes, filter attributes in Vectara can be used to support filtering in Vectara. A filter attribute must specify a name, and a level which indicates whether it exists in the document or section level metadata. At indexing time, metadata with this name will be extracted and made available for filter expressions to operate on. In our data flow, we configure several fields as filter attributes, like the creation time, author, etc., as those are important filters for users in the Vectara app.
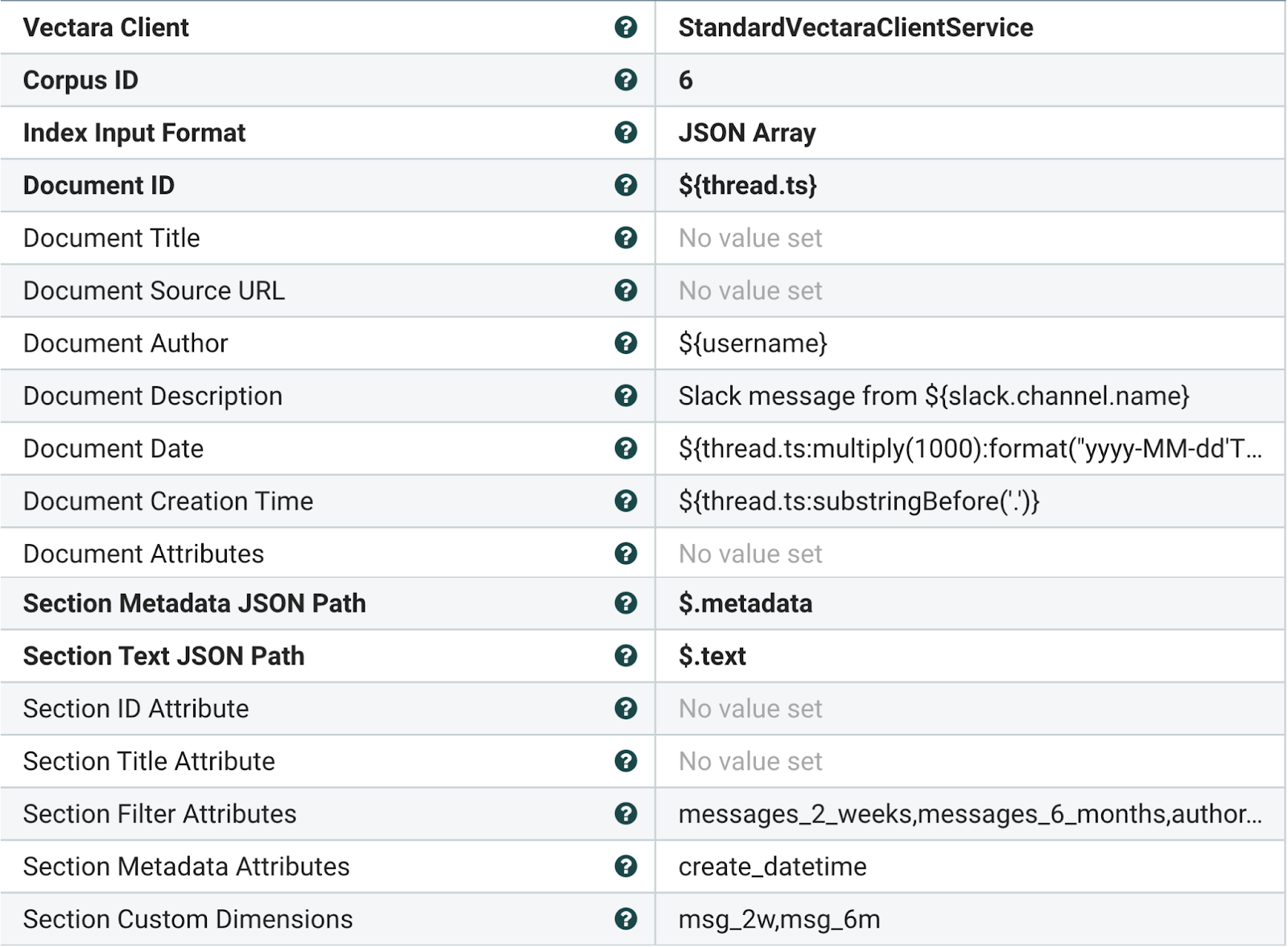
Custom Dimensions
For PutVectaraDocument, it’s important to note the configuration for custom dimensions, as well as filter and metadata attributes. Custom dimensions in Vectara enable users to have a fixed set of additional dimensions that contain user-defined numerical values and are stored in addition to the dimensions that Vectara automatically extracts and stores from the text. At query time, users can use these custom dimensions to increase or decrease the resulting score dynamically!
On our Slack channel, we noticed that user’s who post more tend to be NiFi experts who submit high quality responses. We want to rate content from these users higher. We capture two different metrics to ascertain how frequent a user posts (and thus how accurate their posts are):
- A two week total message count
- A 6 month total message count
These counts are computed at the time the post was made, and they need to be normalized before being used as a custom dimension. Normalization can be tricky because a user who posts more should get a higher score, but it is a non-linear relationship. Someone who posted 50 times in the 2 weeks is not necessarily twice as proficient as someone who only posted 25 times. Another issue is a very active user may have hundreds of slack messages across a couple weeks. We don’t want a single custom dimension score to dominate the other dimensions related to text similarity. We need our returned results to match the query – not just come from a power user.
To solve these issues, Vectara recommends using a sigmoid to normalize these counts. Sigmoids have several great properties:
- The sigmoid’s domain can take in any integer while its range sits between -1 and 1. This allows it to handle any input and prevents a single score from dominating the other dimensions.
- The sigmoid monotonically increases: users who post more get a better score.
- The sigmoid is linear-like across a target interval: users who post enough are scored substantially better than those who post a tiny amount.
In order to properly normalize these custom dimensions with a sigmoid function, we made a few additional changes:
- In order to have the score range from -1 to 1 we modified the function to: 2 / ( 1 + e^(-x) ) – 1
- We want to tune our sigmoid such that someone who only posted once gets a negative score while a user who posts an average amount gets a score of 0. We also want to adjust how quickly the sigmoid rises as a user posts more. We therefore modified the function to
2 / ( 1 + e^(-(x – offset) / (offset / 2) ) ) – 1
We found a good value for the offset is roughly the average user’s post count during the time period. There is a lot we could do to further tune the normalization, but this approach worked well for the use case at hand.
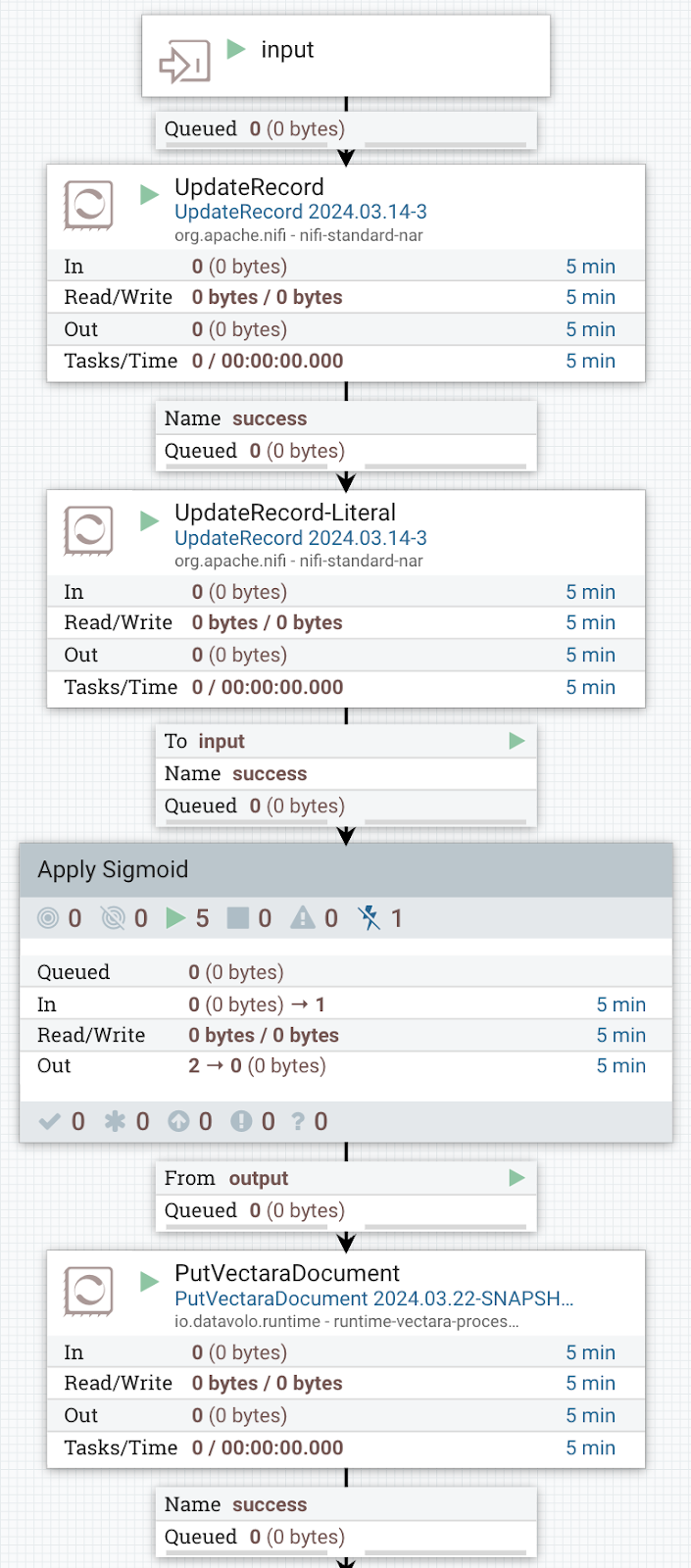
Implementing the scores into our flow can be done using NiFi Expression Language which conveniently supports math expressions. After combining Expression Language with an UpdateRecord processor we properly transformed our Slack post counts into normalized custom dimension scores.
We calculated those aggregate measures in our historical database, and then used them as custom dimensions before indexing the Slack documents in Vectara.
Google Drive Flow
The second part of the content load into the Vectara corpus was the user, administrator and developer guides and tutorial PDFs for Apache NiFi. We were able to pull these guides from a particular Google Drive location, enrich these files with the needed attributes for the Vectara corpus, perform OCR on the documents to extract the important text, and finally load into the same corpus as we are using for our Slack messages, as illustrated below:
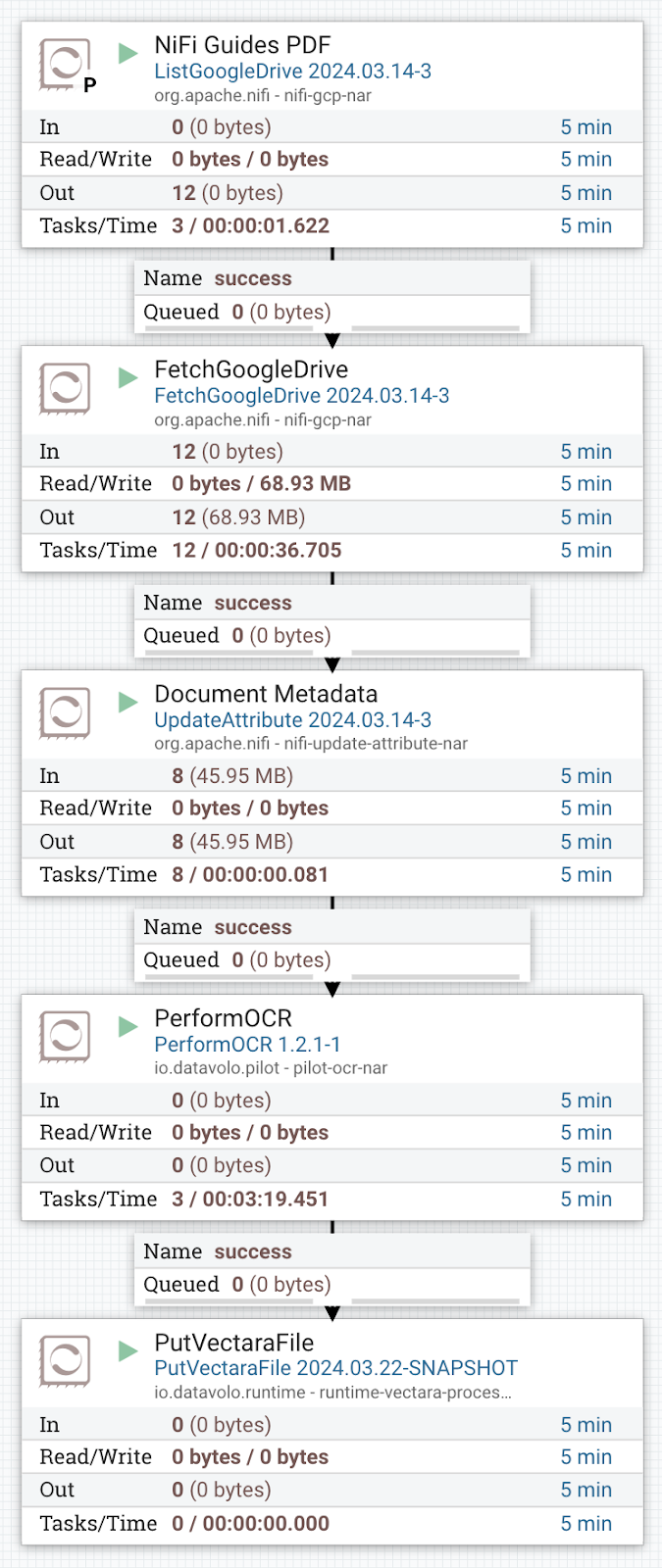
Using Vectara GenAI Platform
Now that the Slack and Google Drive data is being streamed into the Vectara corpus it is very easy to incorporate a Q&A and/or a chatbot experience into your UI.
For this application we will demonstrate the power of Vectara’s serverless RAG platform via two GenAI user interface example experiences, built using vectara’s open-source components:
- https://ask-datavolo.demo.vectara.com/ demonstrates a question-answering interface, powered by the open source vectara-answer project. This type of user interface lets the user ask questions in natural language and see a summarized answer, complete with citations to the raw results from which the answer was derived.
- https://datavolo-chat.demo.vectara.com/ demonstrates a chatbot, powered by react-chatbot – an open source React component. With a chat interface, the user can have a discussion with the data, where the system maintains a memory of the conversation so it remains on point and relevant.
It is of course also very common for client applications to call Vectara’s APIs directly, to add semantic search, Q&A, and conversational AI into their applications.
We will run a few sample inputs, and use that to explain just how powerful Vectara’s RAG system is – especially when provisioned with data via the Datavolo integration.
Question-Answering Example 1
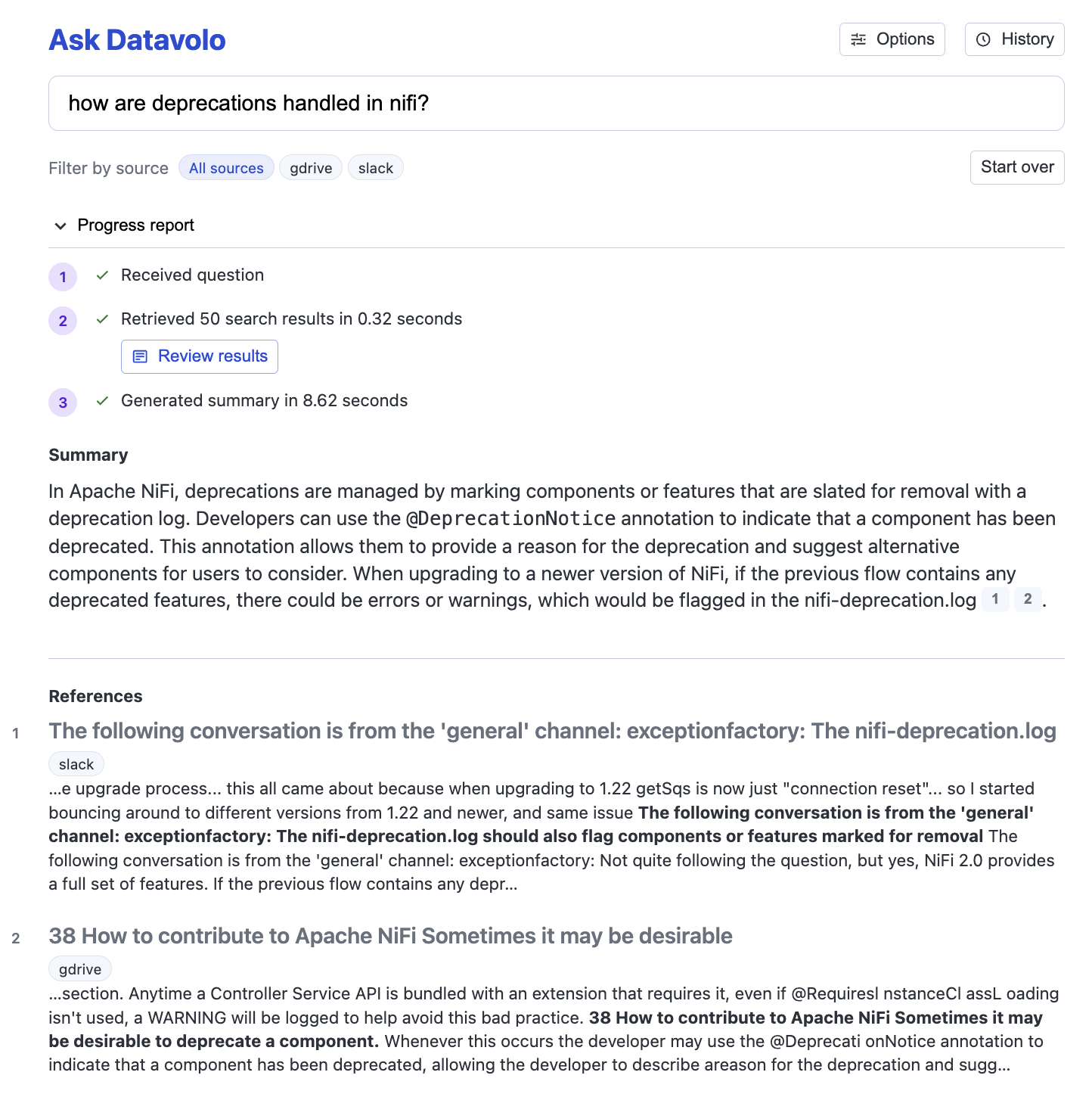
In the first query we see how good Vectara is at answering a user’s question. It first finds the most relevant pieces of information from the Google Drive and Slack data set, and then summarizes them into an easy-to-understand answer. Note that the generated answer includes citations, so you can understand where the answer comes from and you can dig deeper into any of the references if needed.
Query: how are deprecations handled in nifi?
Question-Answering Example 2
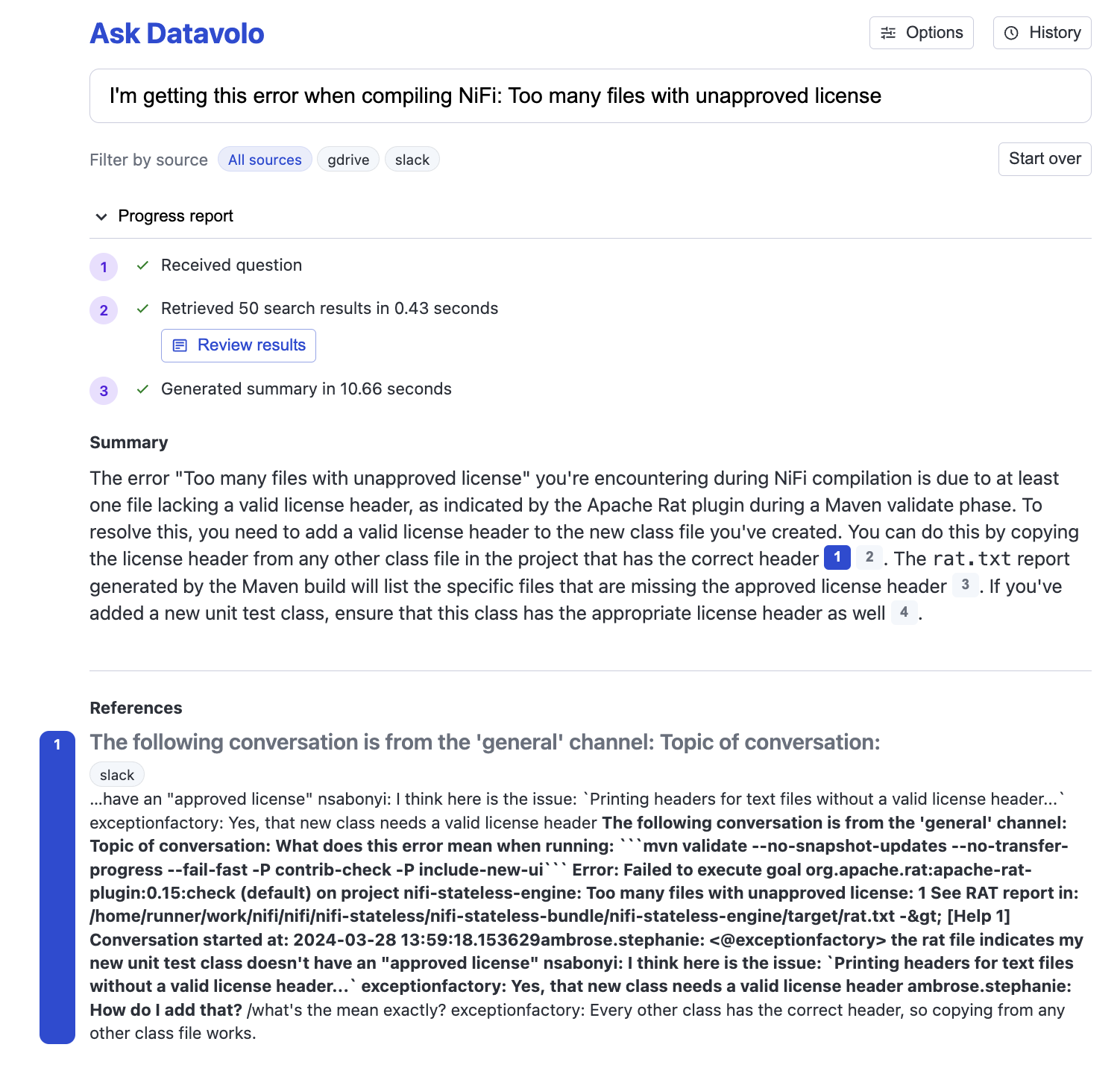
This example shows how Vectara effectively handles queries that are longer, with more nuance than a simple keyword-style lookup. Due to its deep understanding of human language as well as many different data domains, Vectara can quickly provide a fix to even highly technical problems.
Query: I’m getting this error when compiling NiFi: Too many files with unapproved license
Chat Example 1
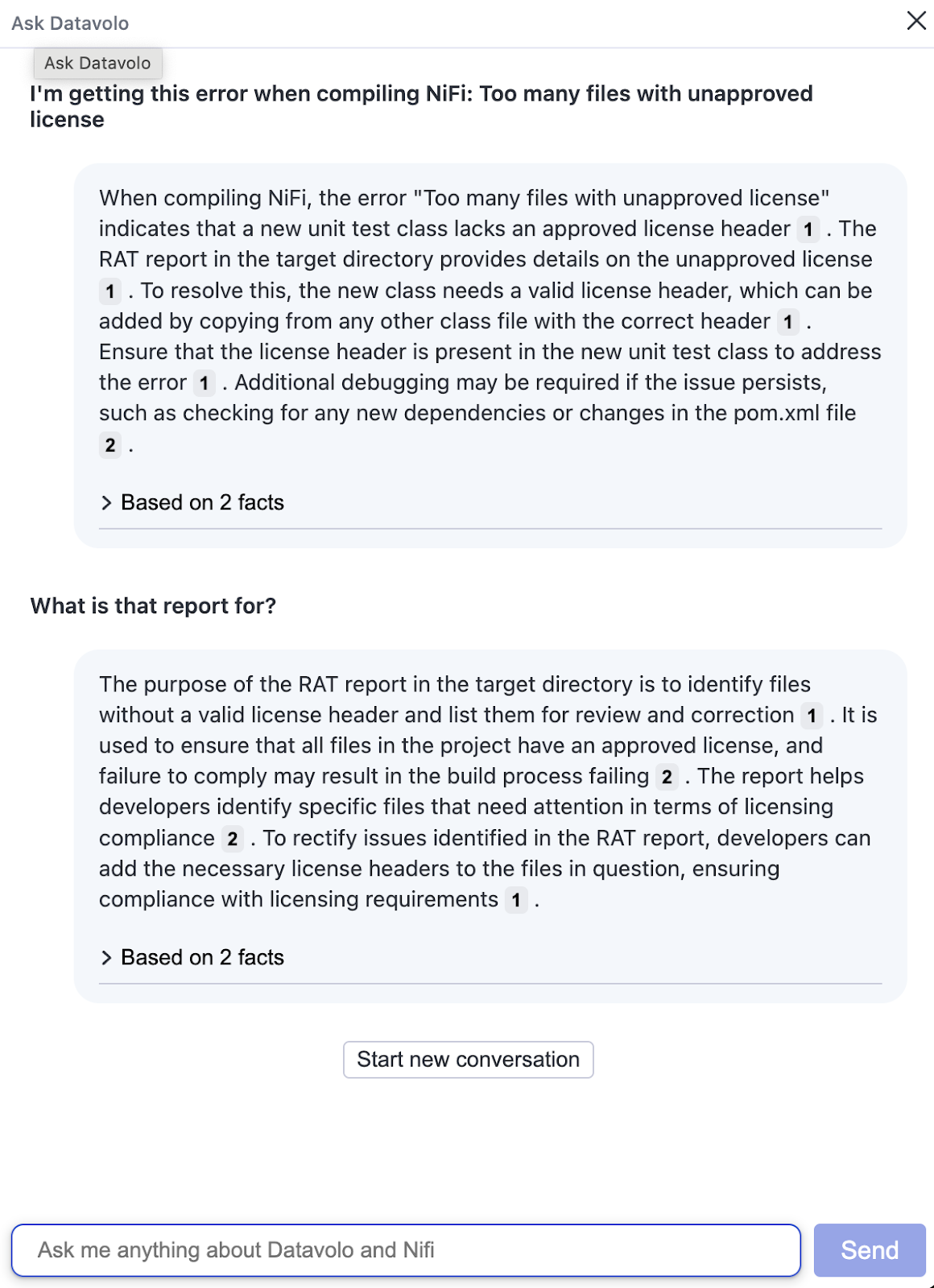
With just two additional lines of code in the Vectara Query API we can add a conversational AI capability, making it trivially easy to add a chatbot experience to your application. Enabling chat mode tells Vectara to retain a memory of the interactions within a given chat session, and adjust its responses accordingly. In the example we use the same starting query as before, but when the second input is provided, Vectara knows that the report referred to is the RAT report mentioned in the first response.
Chat Input 1: I’m getting this error when compiling NiFi: Too many files with unapproved license
Chat Input 2: What is that report for?
Vectara’s API design philosophy is to blend simplicity with flexibility. As seen with the option to enable memory, it is trivial to add query filters, enable rerankers, choose which LLM you want, provide a custom LLM prompt, turn on the Factual Consistency Score (i.e. hallucination guardrail), and do much much more.
Conclusion
In this solution walkthrough, we showed how Datavolo and Vectara can be used as complementary tools within the AI stack to build powerful GenAI apps. We showed the preprocessing steps, including acquisition, extraction, and enrichment of complex documents and data in Datavolo and the integration the Datavolo team has built to index these knowledge bases into Vectara. We saw how Vectara simplifies the RAG and ML pipeline needed for users to get the right insights from these sources of knowledge, driving critical enterprise functionality. Vectara brings trustworthiness to GenAI, by reducing hallucination, providing explainability, enforcing access control, allowing for real-time updatability of the knowledge, and mitigation of intellectual property and bias risks.
We would love for folks to try these solutions out for themselves! Datavolo’s private beta is launching in early April, please head here to sign up for early access. In the meantime, please check out the blogs, Slack community, and product pages.
To get started with Vectara, sign-up for a free account. From there you can easily upload files and start asking questions of your data. Or you can check out our resources for how to get started building an application.