
Apache NiFi acquires, prepares, and delivers every kind of data, and that is exactly what AI systems are hungry for. AI systems require data from all over the spectrum of unstructured, structured, and multi-modal and the protocols of data transport are as varied as the data itself. At the same time data volumes and latency requirements grow ever stronger. In turn this demands solutions which scale up and down then out and in. In other words, we need maximum efficiency and we can’t resort to remote procedure calls for every operation. We need to support hundreds if not thousands of different components or tools in the same virtual machine.
Extensibility is essential
The diversity of data types and protocols means from the outset a key design principle NiFi supports is extension. Out of the box, NiFi offers hundreds of components to handle various types of data from PDFs, Audio, Video, images, JSON, XML, database records, log entries and more. NiFi also understands protocols to exchange data with Google Drive, Amazon S3, SFTP, Email, UDP/TCP sockets, Snowflake, Databricks, Pinecone, OpenAI, AWS Bedrock, and many more. To enable this extensibility NiFi supports isolation of these components and their dependencies from other components. And further NiFi allows users to easily build their own extensions. NiFi often safely colocates thousands of processors representing hundreds of unique data pipelines. This colocation minimizes remote procedure calls, latencies, and simplifies deployment and operations.
But having so many different dependencies in the same JVM means dependency conflicts are a certainty. It also means NiFi needs a model for dependency isolation which builds upon classloader isolation in the JVM. For those not familiar with Java’s Classloader mechanism, here is a reference and an article to set the context. Some of the key concepts to introduce and build upon before we focus on how NiFi works include:
Class Loader
A classloader is a container and mechanism which scans for and loads classes needed to run a Java application. The classloader acts as a cache for class definitions and state store for static values.
Each Java Runtime has built-in class loaders as described here and as illustrated in the diagram below.
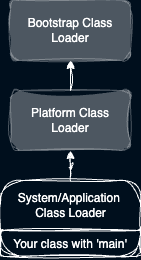
Parent-first Class Loading
Every class loader has a parent class loader except of course the bootstrap class loader that starts the whole party. The JVM loads classes by walking the parent classloader chain until there are no more parents. Then on the way back down the chain the JVM loads the class in the first parent that has it.
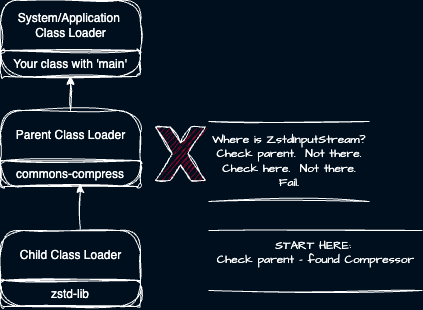
Consider an example where a child class loader holds ‘commons-compress’ and its parent class loader holds ‘commons-compress’ as well. See this diagram to visualize which Classloader will load the class.
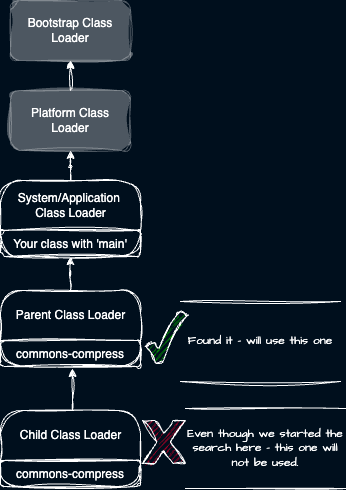
Class loader delegation
When loading the original class it may reference other classes. The other classes must be available at the same level or higher in the classloader hierarchy.
To illustrate this point, consider this example: We want to load a class called ‘Compressor’ from the ‘commons-compress module. The Compressor class depends on a ‘ZstdInputStream’ found in the ‘zstd-lib’ module.
- What if commons-compress and zstd-lib are both in the parent? This works!
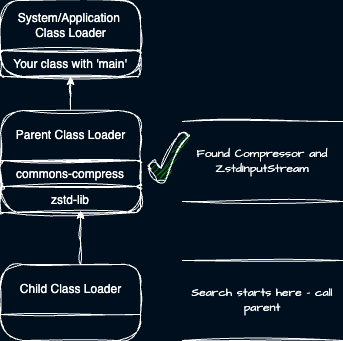
- What if commons-compress is in the child and zstd-lib is in the parent? This works!
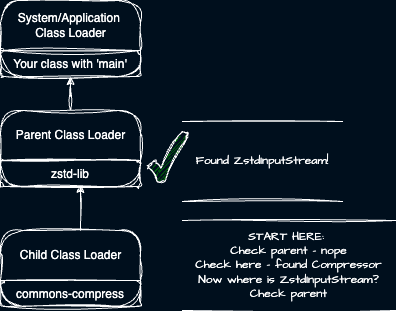
- What if commons-compress is in the parent and zstd-lib is in the child? This fails!
Context Class Loader
Understanding these class loaders and the default delegation model is a good first step. But how does the JVM know which classloader to start loading a class in? In short, the ‘Context class loader’ of the Thread running your code determines which class loader the search starts in. And as the owner of a Thread you get to set this context class loader.
Consider the example of a simple Java app that when given a Thread to execute creates a new child classloader. The new class loader will have a parent of the System class loader which created it. We set the Thread’s Context Class Loader to that new child class loader. Now any classes loaded will have access to that child class loader – subject to normal parent class loading.
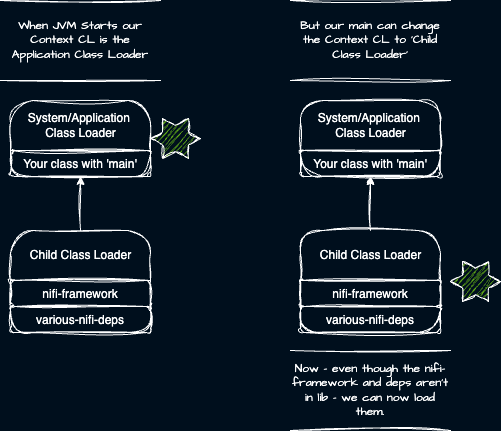
This yields at least two powerful consequences. First, this means we can load new classes/code/capabilities at runtime. Second, we can form a directed graph of class loaders and therein lies the key to establishing class loader isolation!
Native Libraries and Java Native Interface (JNI)
Java applications can also leverage code written as native libraries for the underlying operating system. For example, consider a compression algorithm written in C/C++ for an operating system that outperforms a pure Java implementation. Java JNI can load this native implementation and make it available within the JVM. Native libraries loaded by a classloader becomes available to all class loaders. This behavior differs from normal class loading behavior. Consequently, loading two native libraries with the same name will cause failures.
Static values and class loaders
In Java applications, it is sometimes necessary to store values in static members of a given class. Various frameworks and libraries take heavy advantage of this. The classloader that loads a given class owns the state of its static members. So, if you have the same Class definition loaded in multiple class loaders, they each have their own static values/memory/state.
Putting it all together in NiFi
These fundamental concepts covered thus far are the basis for NiFi’s Class Loader Isolation model. Now let’s put that together to uncover how this really works in NiFi itself.
The packaging concept of NiFi Archive (NAR)
- NARs may package native libraries. NiFi detects these libraries, renames them unique to the NAR, ensuring libraries with the same name can co-exist.
- A NAR is a ZIP archive containing dependent JARs, and resources which implement zero or more NiFi extension interfaces. NiFi extension interfaces include processors, controller services, and reporting tasks.
- A NAR has an optional reference to another NAR which will become its parent in the Classloader hierarchy.
- A NAR may contain a WAR which is a custom user interface to interact with the extension in the NAR.
- A NAR must assume the NiFi Runtime it operates in provides a set of common components. The provided components include the NiFi API which forms the contract for extensions and interaction with the core framework.
- A user can reference a NAR by its group, name, and version. This referencing scheme means NiFi can support multiple versions of the same NAR at once. NiFi supports multi-tenant users, and they all operate on different timelines and maintenance schedules, so this is a key requirement.
NiFi’s class loader hierarchy
NiFi aims to provide NARs with the smallest possible surface area for possible dependency conflicts. A single JAR in the root library increases the probability of conflict for extension NARs. Of course, we do need some dependencies. We only want one copy of logging libraries available to the entire application space. We require NiFi bootstrap logic, the framework itself, runtime components, and the actual NiFi API. The JVM invokes the main method of NiFi bootstrap class in the root lib during startup.
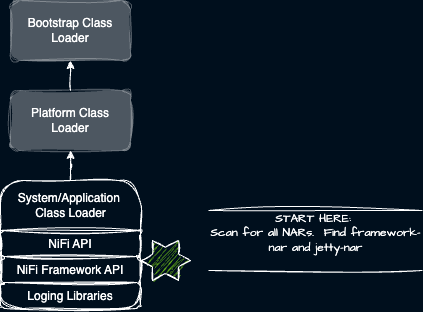
NiFi’s own bootstrapping mechanism then goes about scanning for NARs and creating necessary classloaders for each and chaining them appropriately. One of these NARs is the actual NiFi Framework/Application. The framework and extensions need access to the NiFi Web Server powered by Jetty and a Servlet API and context. Jetty and the Servlet API are in the NiFi Extensions classloader which is the parent of the framework and extensions. Any WARs contained within a NAR will tether to the NAR’s classloader. So here is what the actual NiFi Class Loader hierarchy looks like to start.
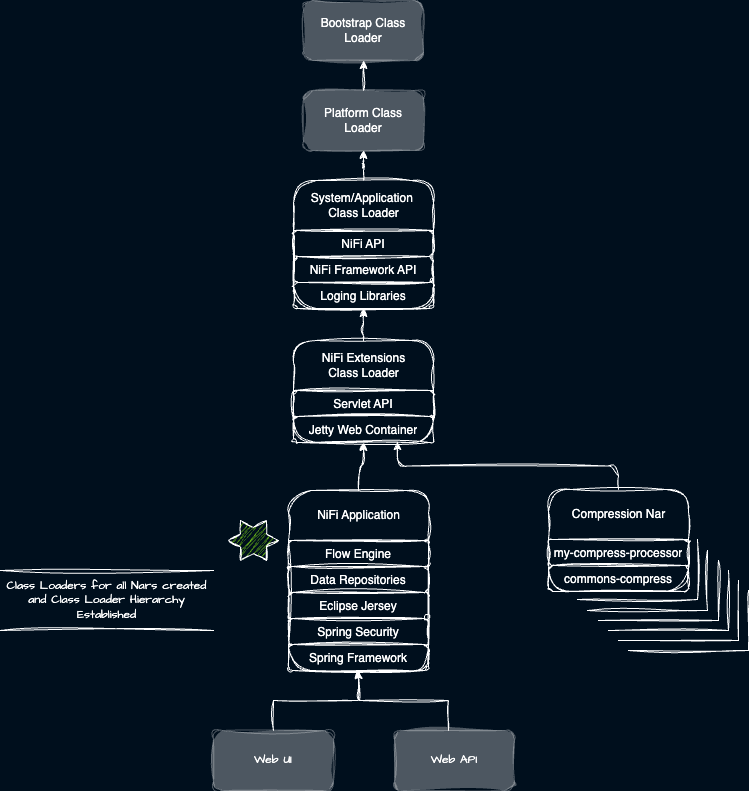
Exploring NiFi’s Component Isolation Model
Having scanned for all the NARs, NiFi constructs the class loader hierarchy shown previously. NiFi also attaches the NiFi HTTP (REST) API and the NiFi User Interface. Components such as the UpdateAttribute processor have a custom user interface (WAR) which attaches as a child class loader. The image below illustrates the class loader structure.
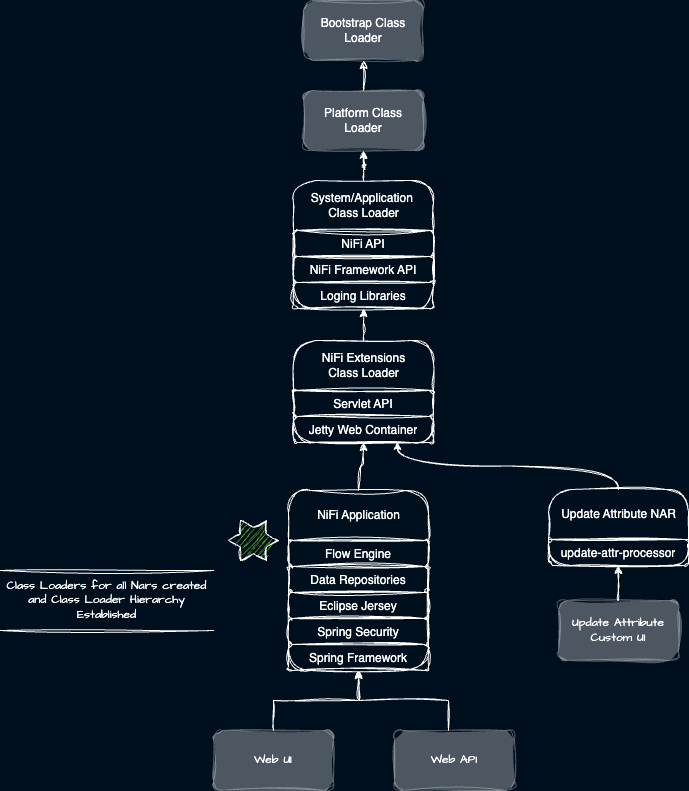
Core framework WAR’s attach to the Framework NAR while all custom WARs attach to their respective NARs. The custom WARs communicate with the framework via the NiFi Framework API found in the root lib and the servlet context in the NiFi extension class loader.
NAR Delegation Model
As described previously NiFi also allows for NARs to reference other NARs which become their parent. This pattern allows us to share common interfaces like SSL Contexts, Kerberos Contexts, Database Connections, and other resources as shared services across many NARs. As NiFi scans for all these NARs it constructs a graph of class loaders that represent these relationships. This image shows how that looks in practice from a Class Loader perspective.
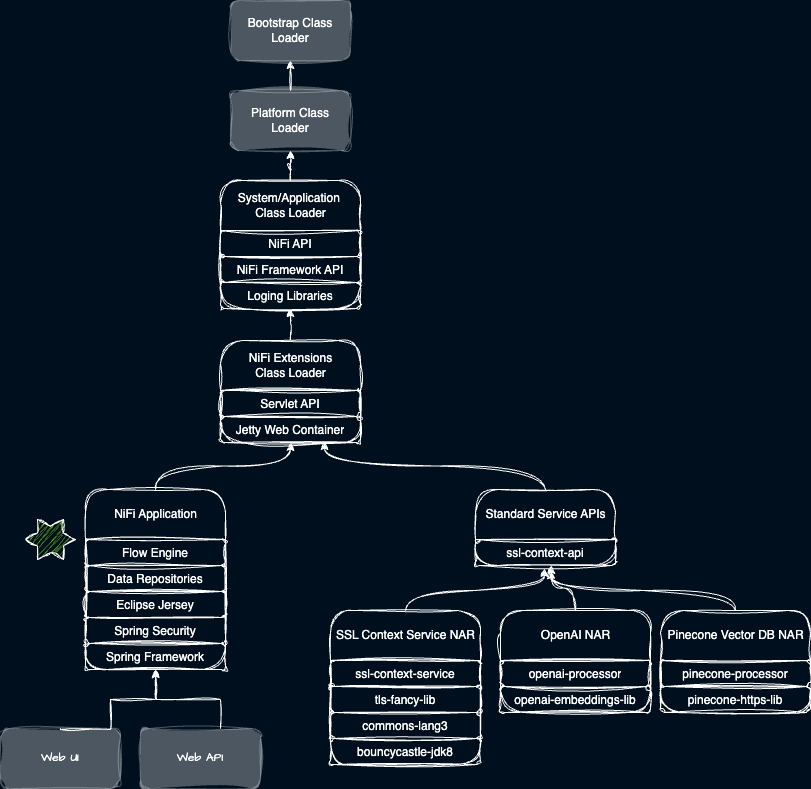
At this point in its startup procedure NiFi has created Class Loaders for all the NARs and established their hierarchy. Now it is time to fire up the framework and start making data flow! To do this we leverage the capabilities of Java class loading we’ve already described. Our application class loader sets the current Thread’s context class loader to the Framework NAR and invokes its bootstrap code. A cascade of initializations then fire up Jetty, establish data repositories, create the flow graph, thread pools, and more.
Setting the right class loading context
The NiFi application framework at its core is a Flow Engine. The engine operates a thread pool that shares out threads for tasks by any component or extension in the system. The Flow Engine hands off Threads to execute but it does not itself know which component is about to run. Consequently the engine cannot preemptively set the context classloader.
Instead, the Flow Engine establishes as its ‘Class Loader Context’ a special redirecting Class Loader. This special class loader analyzes the call stack of a loadClass call, detects the NiFi extension implementations and then looks up the correct class loader, and pins its context to that component. In this model the engine does not know which component it is serving still provides fine grained component isolation!
Following along as the context changes
Consider an example flow which fetches documents, generates OpenAI embeddings, then sends that data to Pinecone. At first the Flow Engine holds the context. The classloader context starts as shown.
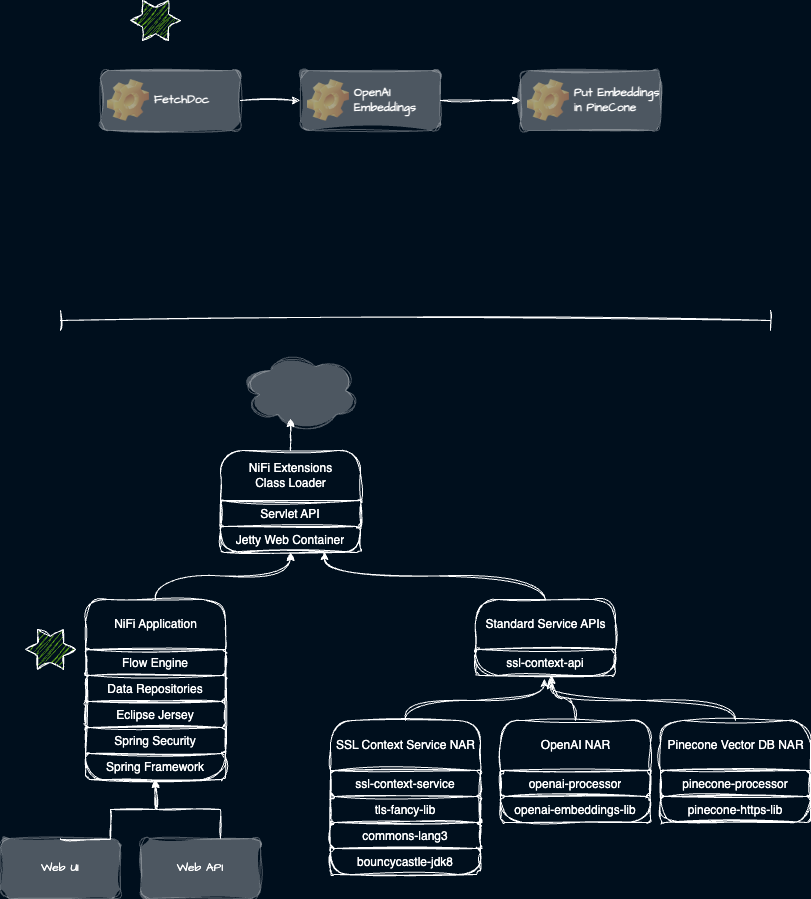
We need to execute the OpenAI component to generate embeddings. We set the context class loader to be the special lookup mechanism. The engine hands control to the OpenAI NAR which starts running its code immediately intercepted by the special lookup. The special lookup finds the OpenAI class and then pins the context classloader to the OpenAI NAR. Then subsequent class loading calls by the OpenAI code will find its isolated classes.
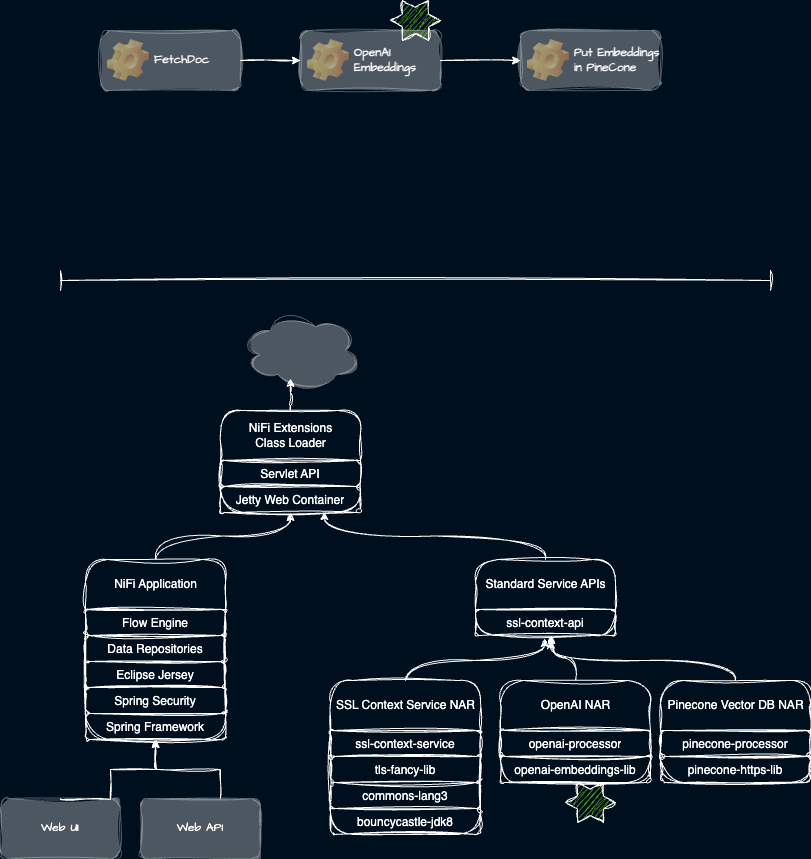
At this point the flow is off and running and NiFi can capture, transform, and deliver data at impressive scale. The classloader hierarchy and isolation mean we can minimize conflicts and make it easy for developers to extend NiFi’s capabilities. Still a few challenges remain to overcome.
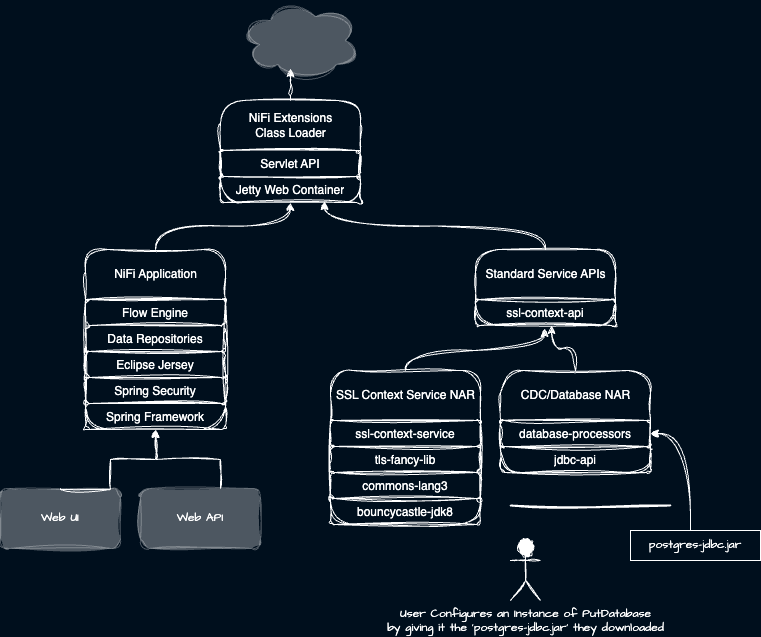
User provided dynamically added code
Another challenge is that some libraries need to be provided by the user rather than within a NAR. For this, we can declare a given NAR requires its own unique class loader for every instance of that component. Further we can specify that each such component supports dynamically adding code. The user can supply at a specified location these additional JARs they need such as a specific JDBC drivers. Fellow Apache NiFi PMC member Bryan Bende describes this well in this blog.
Overcoming excessive use of static values
While powerful, what we have discussed so far does not provide isolation if a NAR’s library relies on static values. All instances of a component in that NAR will have visibility to the static value(s). Some libraries do rely on static member values which can defeat naive classloader isolation. For example, the Hadoop Client libraries, used in various components including Apache Iceberg, Hive, HBase, and more, rely on static values for important security context information. Providing component isolation requires providing each instance of these components their own classloader.
Creating isolated classloaders per instance of these components leads to substantial memory consumption due to excessive duplicative loaded classes. NiFi allows developers to counteract this excessive memory usage by accepting guidance on when to create isolated classloaders. For example, the developer tells the framework to only create isolated instance classloaders for Hadoop components when the security principals differ.
We’ve covered a lot of ground. NiFi can support powerful isolated components with various differing and even conflicting dependencies to include native libraries. You have a greater appreciation for the fundamentals of how that classloader isolation works. Note that a wonderful knock-on effect here is that loading new extensions to NiFi, or even new versions of existing extensions, at runtime, is as trivial as is loading them on startup!
Conclusion
This provides an excellent foundation for operating NiFi in elastic scaling environments such as Public Cloud and/or Kubernetes. What we’ve described explains how a single NiFi node, and often NiFi is clustered with many such nodes, handles thousands of components running simultaneously handling a diverse set of data formats, schemas, and protocols. Data Engineers use NiFi due to this model to isolate critical dependencies and drive efficient resource utilization. This flexibility and efficiency is central to why NiFi supports data capture, transformation, and deliver involving Edge/IoT systems, Data Lakehouses, traditional Databases or Data Warehouses, and now Generative AI! This also explains why NiFi was such a natural choice for Datavolo to build its products around.
Today, NiFi powers Generative AI pipelines so we’ve added first class support for developing and executing extensions in Python. The Python world offers tremendous support for data parsing, chunking, embedding generation, ML model execution, and more. A follow-on article will describe how this isolation model has been carried through to these Python components as well.