
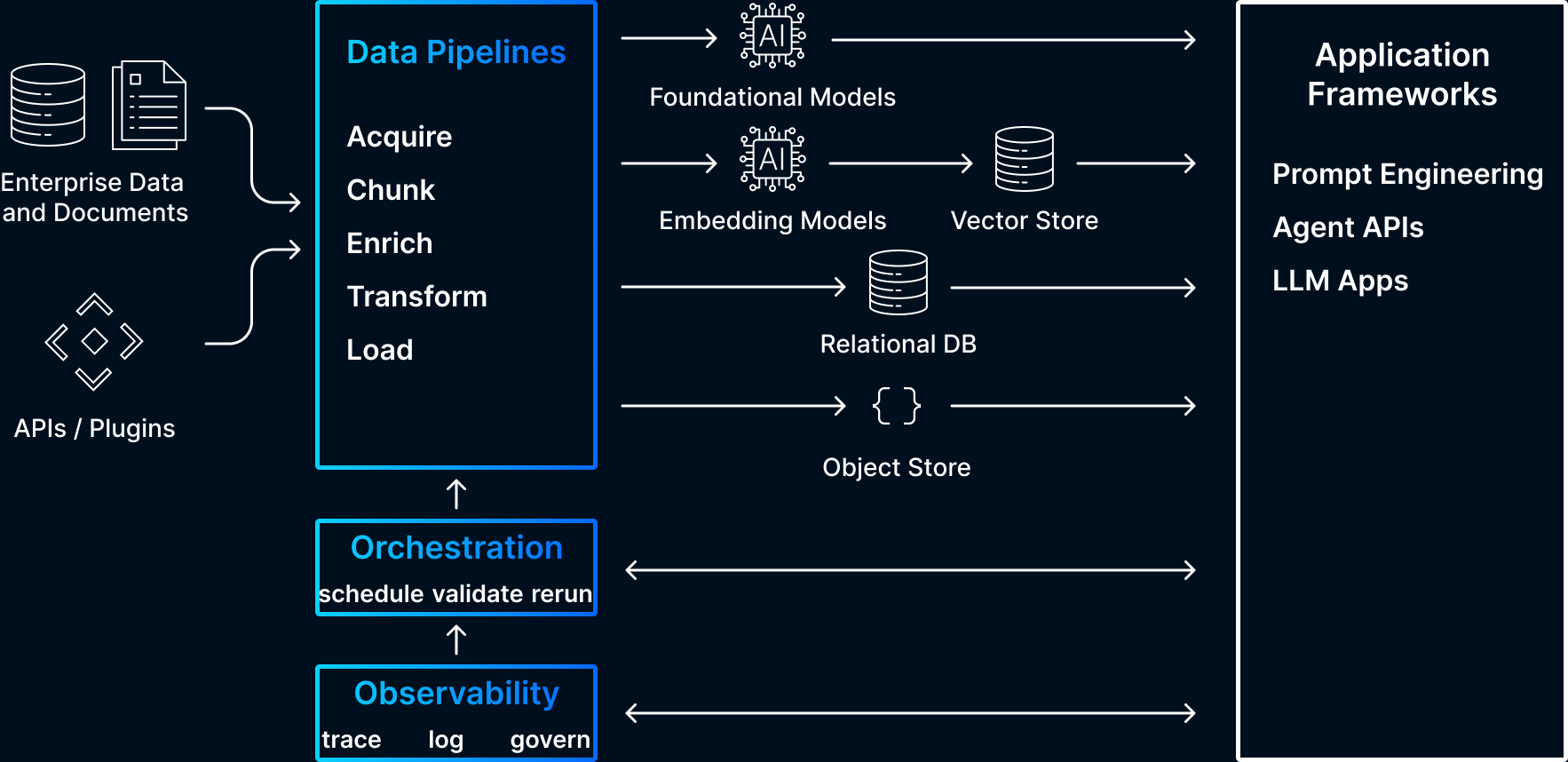
The Evolving AI Stack
Datavolo is going to play in three layers of the evolving AI stack: data pipelines, orchestration, and observability & governance.
The value of any stack is determined by the app layer, as we saw with Windows, iOS, and countless other examples. While prototyping AI apps can be surprisingly easy, the path to production and automation is proving challenging for many. A major reason for this is the open questions that exist at every layer of the emerging stack. The design patterns are nascent and evolving, especially those patterns related to connecting data and documents with foundational models. One major cross-cutting challenge is evaluation–questions like how well is retrieval working, what is the quality of the model output, has the quality recently changed? In a future blog, we will go into greater depth on how Datavolo is incorporating evaluation into our pipeline health and observability features.
Engineers’ initial instinct was to build apps directly on LLMs–in the absence of a fully-fledged AI stack–but hallucinations and the need to add contextual data drove them down the rabbit hole of fine tuning, as well as towards in-context learning patterns like RAG to anchor model output on contextual documents and data.
We’ve also started to see the agentic pattern of LLM + Tools emerge for many AI apps, whether that’s a retrieval tool to augment model knowledge, a math tool, or a coding one. This is a compelling design pattern where the model itself makes decisions to interface with the right systems at the right time, and we’re seeing a lot of focus in this direction with the launch of OpenAI’s Assistant API as well as startups.
These design patterns, especially the focus on in-context learning, have led to several new solutions in different layers of the stack: app frameworks like LangChain and LlamaIndex, embedding APIs and vector databases like Pinecone, and new capabilities in data pipelines, orchestration, and observability & governance.
Some important prior work we’d like to note here are The Generative AI Stack: Making the Future Happen Faster by Madrona and the Emerging Architectures for LLM Applications | Andreessen Horowitz. These emerging POVs on the AI stack are aligned with our thesis on where Datavolo will be most impactful to enterprises and their need for multimodal data pipelines.
Where does Datavolo fit in?
Datavolo is a tool for data engineers supporting AI teams. It provides a framework, feature set, and a catalog of repeatable patterns to build multimodal data pipelines which are secure, simple, and scalable.
Data engineers need tools to build multimodal pipelines across the continuum of foundational model integration and customization. The use cases these tools need to support span the continuum of in-context learning from prompt engineering to advanced RAG to agent API integration. Datavolo is designed from the ground up to support these use cases and, importantly, provides features for pipeline observability and governance, including evaluation of the retrieval system
ELT as a pattern is far less natural in the multimodal setting. The systems that produce multimodal data are not relational. The systems in which multimodal data land–embeddings and vector DBs, indexes and search platforms–are not intended to be data engineering platforms, where SQL based code is pushed down to the in-databases compute layer.
This will put the emphasis on transformation in the traditional ETL architecture, and on multimodal data frameworks that can cope with the reality of bridging these non-relational data producing systems with the emerging consuming systems.
All these different ideas and open research on design patterns for AI apps go to show a few key things:
- Flexibility will be critical for AI engineers as the ground will continue to shift under their feet as the stack evolves and open questions are answered
- Data pipelines and orchestration capabilities will be crucial to building valuable AI apps. The key data engineering tasks of extraction, cleansing, enrichment, and loading (into data stores like vector databases and otherwise)
- App frameworks will be important and their focus will be on specific patterns like prompt chaining, memory, chat UX, etc. They will be most useful to developers in absorbing complexity as the different design patterns evolve
Datavolo was built to be extremely flexible, to provide the tooling data engineers need to handle multimodal data, and to integrate out of the box with the full AI stack to provide a secure, scalable, and codeless developer experience. Please reach out with your feedback, we’d love your insights on the challenges your organization has faced with multimodal data!