
Data Engineering for Advanced RAG
Datavolo helps data teams build multimodal data pipelines to support their organization’s AI initiatives. Every organization has their own private data that they need to incorporate into their AI apps, and a predominant pattern to do so has emerged, retrieval augmented generation, or RAG. We’re finding that successful AI apps aren’t built directly on top of LLMs, they’re being built on top of AI systems. These systems come with additional functionalities, including retrieval capabilities to support RAG.
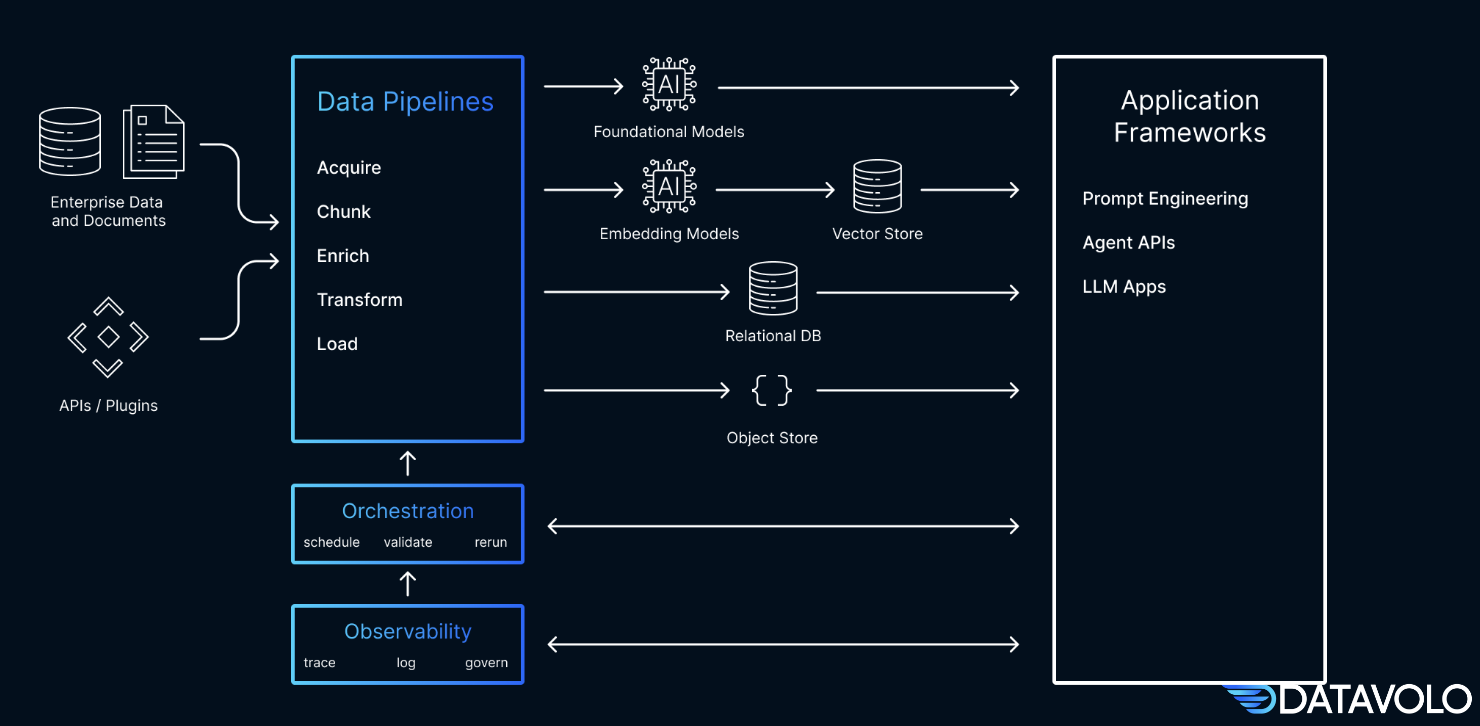
In order to build robust retrieval capabilities, teams need a production-ready data pipeline platform that can extract data from multimodal sources, clean, transform, enrich, and distribute data at the right time and in the right form. In the case of RAG-based apps, that right form is usually vector embeddings, a data representation that carries within it semantic information that was generated during model training. For more information on Datavolo, please read this post and related posts on Datavolo’s blog. In this blog, we’ll review a data pipeline design for an advanced RAG pattern and we’ll discuss why we consider Pinecone an ideal fit for storing and retrieving these embeddings.
Enhancing RAG
In basic RAG pipelines, we embed a big text chunk for retrieval, and this exact same chunk is used for synthesis. But sometimes embedding and retrieving big text chunks leads to suboptimal results. For example, there might be irrelevant details in a big chunk that obscures its semantic content, causing it to be skipped during retrieval. What if we could embed and retrieve based on smaller, more semantically precise chunks, but still provide sufficient context for the LLM to synthesize a high-quality response? This is an advanced RAG pattern known as “Small-to-Big”
Using a sample dataset from the novel Alice in Wonderland, let’s take a look at how the “Small-to-Big” pattern can resolve some of the quality issues that basic RAG encounters.
Results
Let’s first consider two basic RAG patterns:
Pattern 1 – Large Chunks: In our base case, queries are run and synthesized against large chunks of text.
Pattern 2 – Small Chunks: Similar to the base case but the chunks sizes that have been tuned to be much smaller.
Below are two sample queries with a response from both patterns:
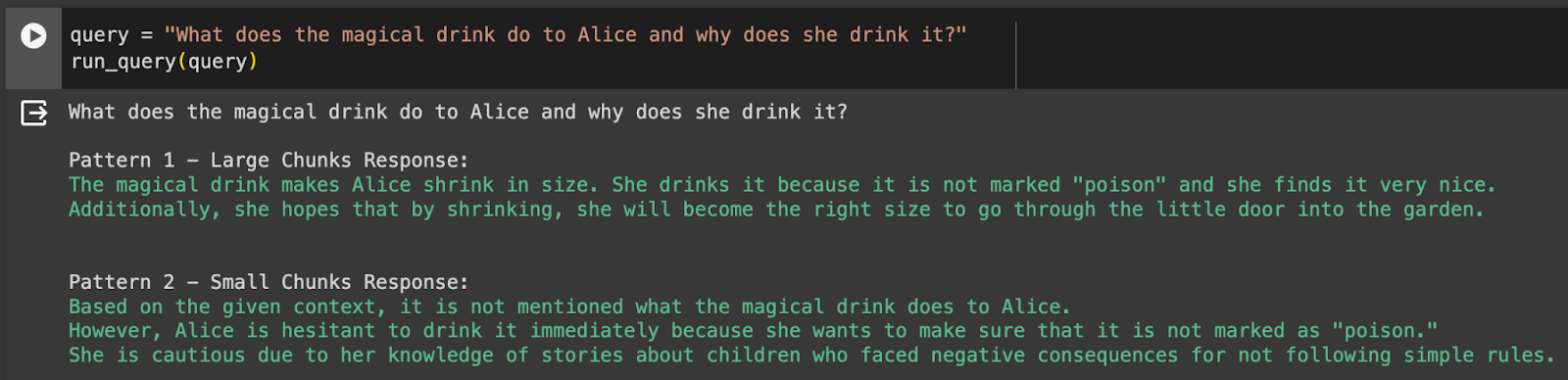
We can see that the large chunks pattern gives a good response however the small chunks pattern did not retrieve enough text to generate a full response. To mitigate, it added ancillary information about Alice that is nice to have but not what we wanted.
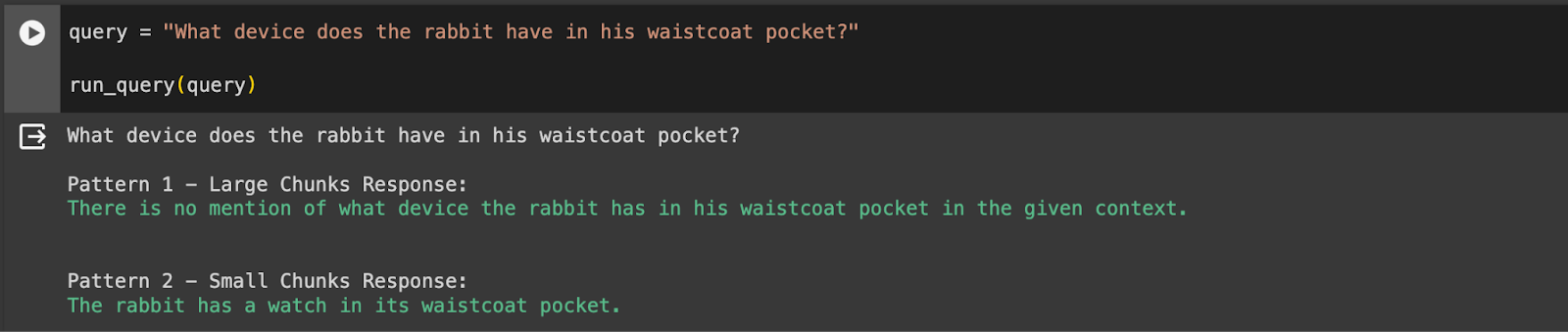
The small chunks pattern correctly answered the question. However the large chunks pattern failed to find the correct chunk of text that matches the query. This shows that tuning the chunk size is insufficient to get the best response across multiple questions. When the chunks are large we have a larger context to have good synthesis of responses but our recall is less specific and may miss returning the most relevant text. For small chunks we have the reversed problem. The recall is more accurate for certain queries but sometimes we don’t have enough text available to generate a proper response.
The root problem is we are using the same data for both querying and synthesis. If there was a way to decouple them, we could conceivably get better results. This is where the RAG pattern known as “Small-to-Big” comes in. The idea is to run queries across small chunks of data, but run synthesis over large chunks of data. Each small chunk of data we query will then link back to a large chunk of text which is used for synthesis. Ideally this should give us the best of both worlds. Let’s see how well it works.
Pattern 3 – Small-to-Big
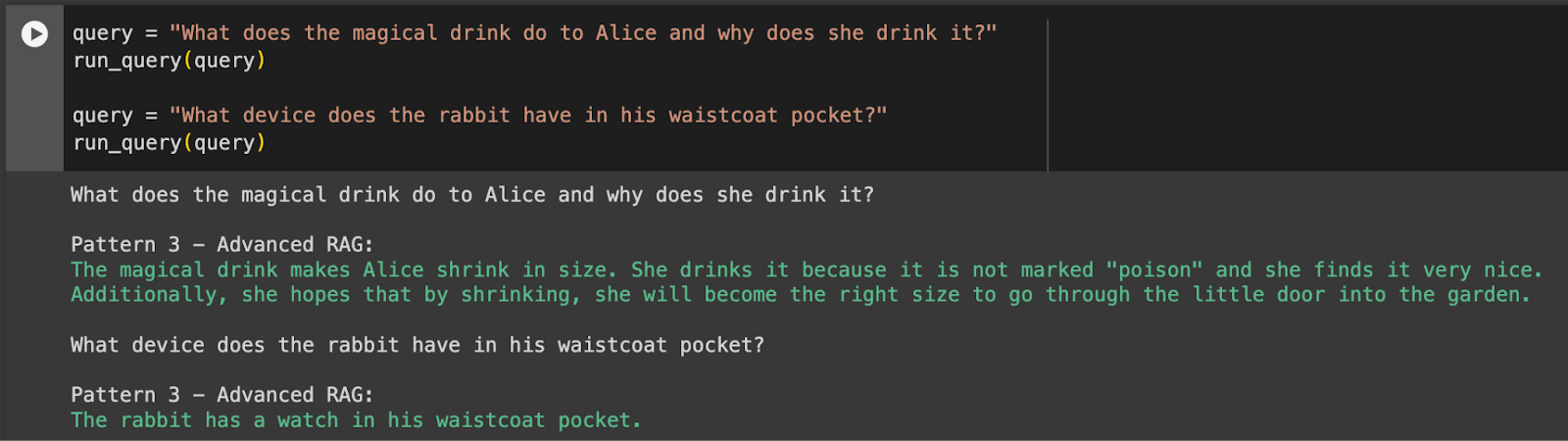
Awesome, we can see here that the Small-to-Big pattern benefits from the best of both worlds with better recall and synthesis! Now that we know the benefits of advanced RAG, let’s show how a Datavolo and Pinecone architecture is a great fit for implementing this pattern. We’ll cover this use case and how we built the data pipeline.
Datavolo & Pinecone
But before we dive into the implementation, let’s give a quick overview of our tools, Pinecone and Datavolo.
How Pinecone fits into this architecture
RAG relies on a robust way to find the relevant chunks of text to send to the LLM. Vector databases are needed to find semantically relevant text for our queries. Pinecone is the optimal vector database because of its compelling features for storing and searching data:
- We wanted to design for high performance for a large volume of embeddings, and we’ve been impressed with throughput, especially when batching requests. We need a solution that scales and a single Pinecone index can load a whopping one billion vectors with an impressive 4.2 billion dimensions each
- We wanted a serverless, cloud-native experience so that we wouldn’t have to spend a lot of time and effort standing up any infrastructure
- We found metadata filtering functionality to be expressive and useful, in concert with semantic search, for some of our use cases
- We were intrigued by Pinecone’s out-of-the-box hybrid search capabilities that support both dense and sparse vectors, and provide automatic re-ranking of results
- Pinecone’s tutorials were incredibly useful in helping us learn about RAG and getting started on our design and architecture
Intro to Apache NiFi and Datavolo
If you’re already familiar with Apache NiFi or Datavolo, you can skip this introductory section.
Datavolo is a great tool for implementing the backend data engineering tasks for populating our vector database and automatically keeping it up to date. Datavolo makes the job of the data engineer far easier due to some core design principles. Let’s define a few foundational abstractions in Datavolo and Apache NiFi so that we can better explain these design principles, please find more details in the NiFi User Guide and in-depth Guide.
- FlowFiles are at the heart of Datavolo and its flow-based design. The FlowFile represents a single piece of data in Datavolo. A FlowFile is made up of two components: attributes (metadata made up of key/value pairs) and content (the payload).
- Processors are components in Datavolo that act on the data, from sourcing the data, to transforming it, and delivering it to end systems.
- A Dataflow is a directed graph of Processors (the nodes of the graph) connected by Relationships (the edges of the graph) through which FlowFiles flow in a continuous, event-driven manner.
With these definitions out of the way, let’s review some core design principles.
- Datavolo provides a visual, low-code experience that is easy to use and ships with hundreds of out-of-the-box integrations to the AI ecosystem–sources, targets, embedding models, LLMs, vector databases and more.
- The UI is not only the dataflow designer but it also instantiates and represents the live data pipeline itself, with no code to deploy. You can think of this as “UI-as-infrastructure” or an analogy we like is “Jenkins is to Airflow as Kubernetes is to Datavolo”, due to the declarative nature of Datavolo pipelines.
- Datavolo handles big data from the ground up. From Terabyte sized files to millions of records per second Datavolo can handle any type of multi-modal dataset. It features concurrent thread scaling within a single node as well as multi-node horizontal scaling built in. Datavolo automatically provisions additional compute nodes to match your processing needs.
- Datavolo is a scalable, fault tolerant, enterprise streaming system. Data can be ingested in an event-driven fashion, and automatically processed within the dataflow. Experimental flows in development can rapidly be deployed to Production and immediately scaled to process Petabytes of data.
- For processors that integrate with external sources, targets, and APIs, Datavolo maintains the integrations as APIs change and new versions are released. Processors themselves are versioned for backwards compatibility.
- Datavolo makes it easy to interactively update pipelines on-the-fly, as well as to replay previous data. Users of Jupiter notebooks will find NiFi’s ability to instantly apply and review updates familiar and refreshing.
- The use of custom processors provides a highly extensible and modular system
- Datavolo provides a secure and compliant infrastructure with a robust provenance system built in. Security, auditing, and data tracking is built into the foundation of NiFi rather than being tacked on.
Processors
Our RAG flow employs several processors which come out of the box with Datavolo.
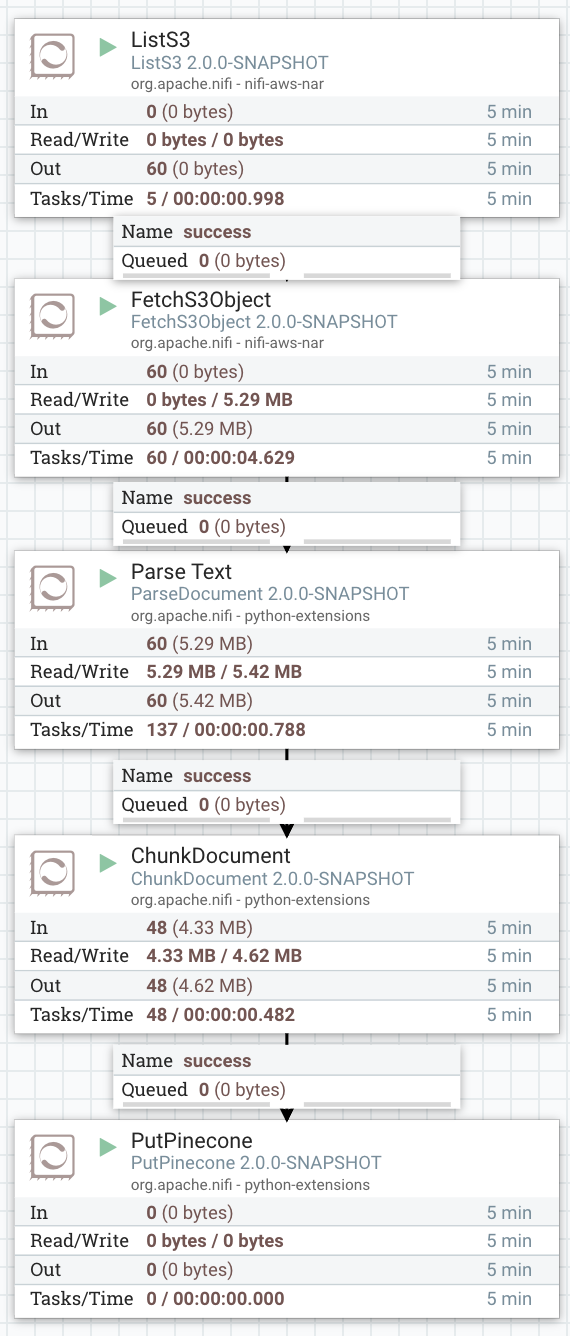
ListS3 and FetchS3Object processors are used to grab data from an S3 bucket. As noted above, any new files that land in S3 will automatically be ingested and processed within the data flow. That means the retrieval system will always have the latest and greatest updates to documents.
ParseDocument is a new AI-powered processor that can read in PDFs, plain text, and other formats and output a common json format for text. ChunkDocument chunks our input into manageable pieces (for those new to chunking strategies, there is a nice intro here). ParseDocument uses the unstructured library from unstructured.io, as well as models like Chipper. ChunkDocument uses LangChain’s API for generating the chunks. Datavolo uses NiFi’s new Python extension capabilities to integrate with these AI Python APIs. By using Datavolo, we can rapidly productionize AI workflows that use LangChain or Unstructured.io.
PutPinecone handles integration with Pinecone. It creates embeddings using a configurable embedding model (defaulted to OpenAI’s text-embedding-3-small embedding model) and persists the embeddings on Pinecone’s cloud service. It is very simple to get up and running with Pinecone. After making an account, all that is needed is obtaining their API key and creating an initial Pinecone Index.
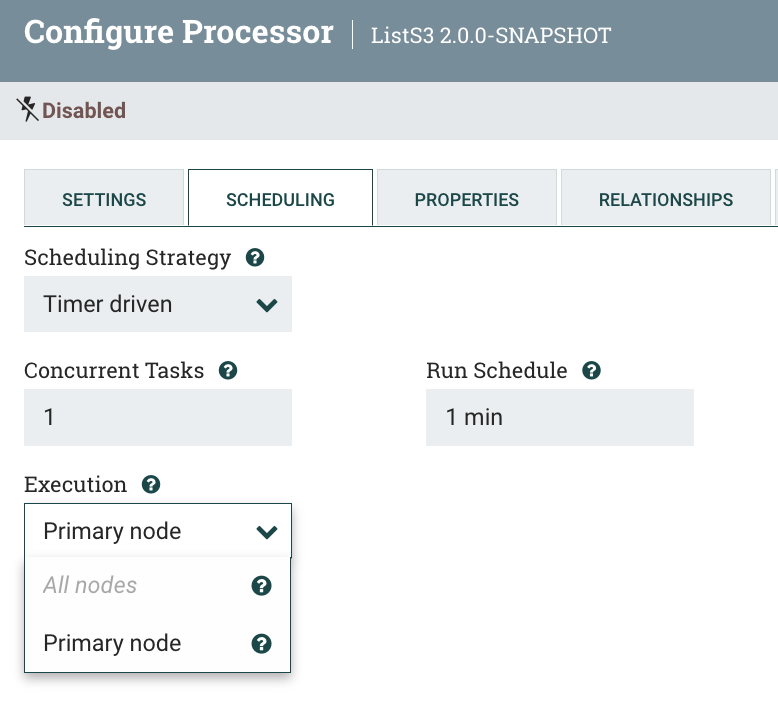
In order to meet latency requirements, we sometimes have to process large documents in parallel. Fortunately, Datavolo is built on kubernetes and can easily scale up and down to process FlowFiles in parallel as a clustered service! For large documents that we need to parse and chunk, we can parallelize this processing within Datavolo, which is a clustered service built on kubernetes and can scale up with greater volume.
Implementing with Datavolo
Before building the advanced RAG pattern let’s start with basic RAG which can be implemented with an ETL workflow in four major steps:
- Extract: ListS3 and FetchS3Object work together to pull all data from an S3 bucket into our system
- Transform: ParseDocument and ChunkDocument are new AI-powered processors as described above. They read documents in various formats and chunk them into manageable sizes.
- Embed: PutPinecone uses OpenAI’s Embeddings API to create vectors from the text
- Load: PutPinecone then stores the generated embeddings in Pinecone. As discussed in the motivation section, these embeddings provide context to the LLM during synthesis to serve user queries
10 minutes in Datavolo’s UI and a few Datavolo processors later we have the following flow:
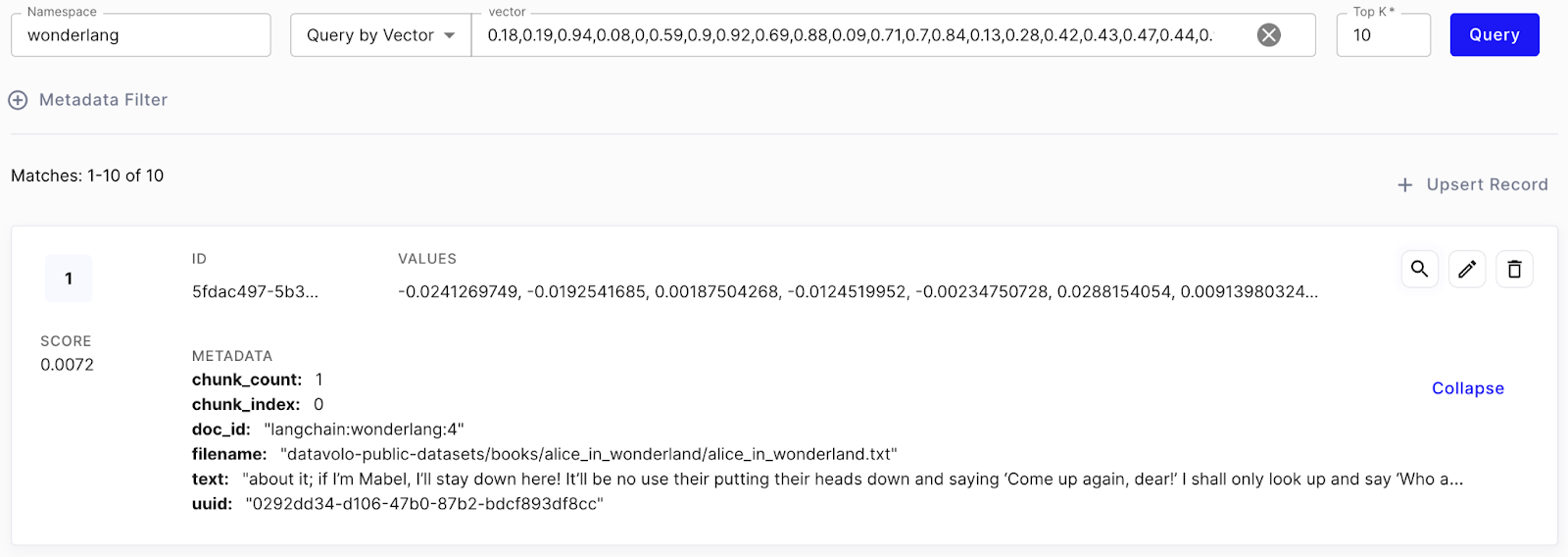
After running the flow we can use Pinecone’s UI to verify our data. Pinecone’s UI is great for ensuring our embeddings were created properly.
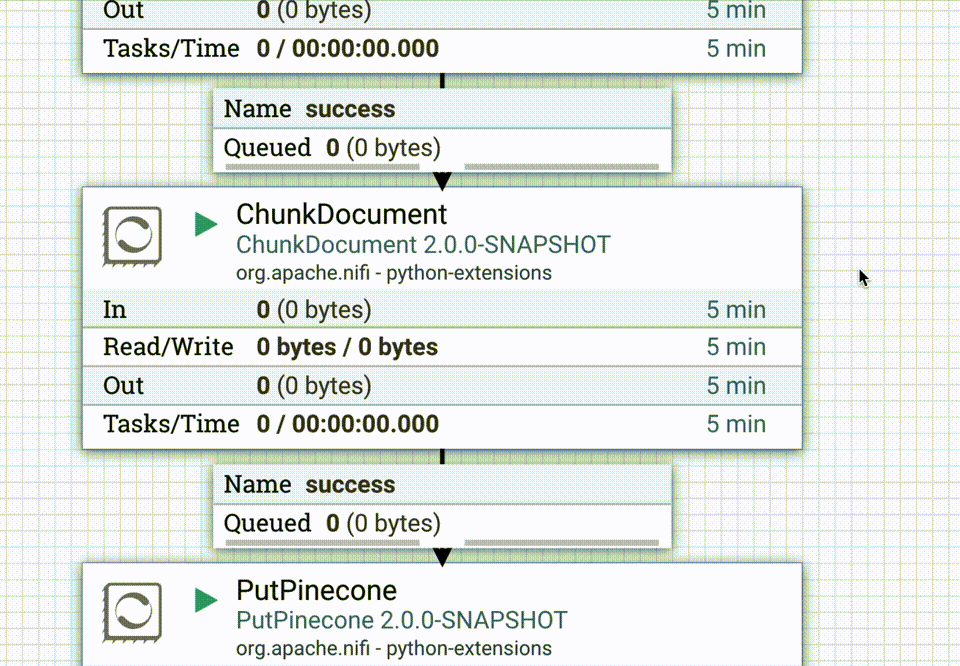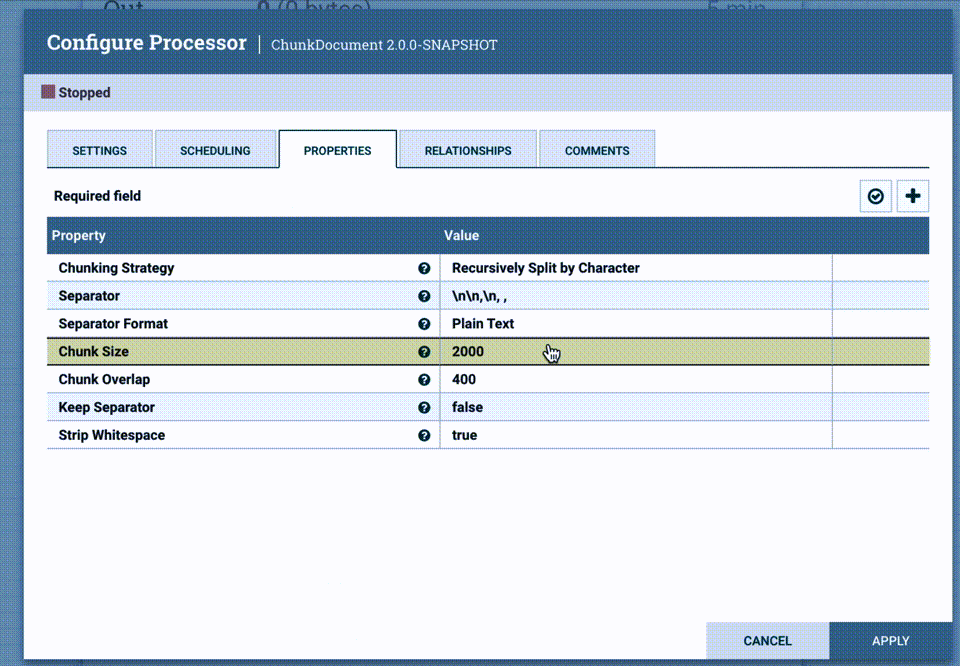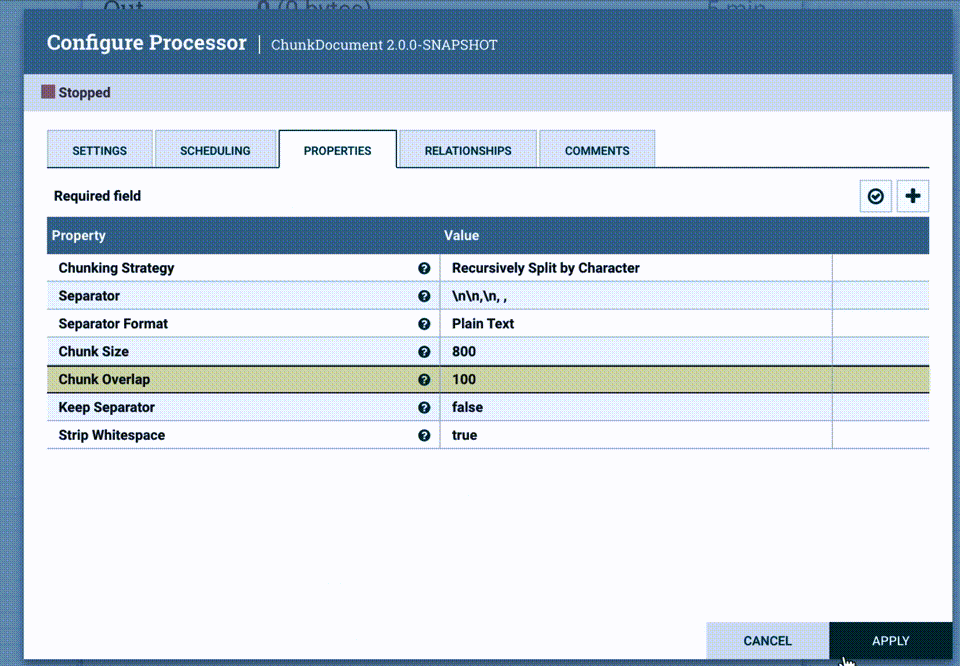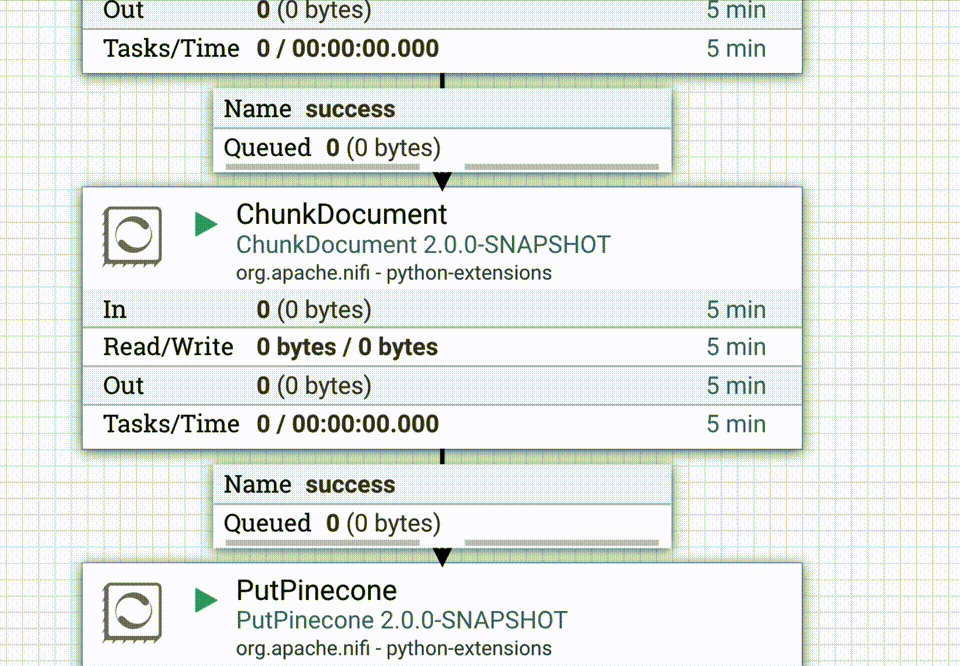
As we mentioned before this basic RAG pattern is sensitive to the chunk size. We can quickly test multiple chunk sizes by editing the configuration in the ChunkDocument processor, it will only take a second.
While this helps a little bit, we’ll need to implement the “Small-to-Big” pattern to improve our results.
Design and Implementation
We need to extend the current Datavolo pipeline to implement the “Small-to-Big” pattern so we can balance the efficacy of both retrieval and synthesis. We can use LangChain’s ParentDocumentRetriever within the dataflow to create the different-sized chunks to implement this pattern. This specialized Retriever both embeds and writes smaller chunks to Pinecone, and uses Datavolo as a serving layer for the docstore (backed by Redis for low latency). We chose to use Pinecone for its vector similarity search and metadata filter capabilities which are necessary to retrieve embedded small chunks with additional metadata.
It is useful to store the parent documents in Datavolo as this provides flexibility to use different chunk sizes, i.e., different document splitting strategies, for different synthesis use cases. For example, we can store chunks tied to sentences, paragraphs, pages, and even entire chapters in the document chunk hierarchy. Since we store the associated metadata with the small-chunk embeddings we write to Pinecone, we will have a pointer to each level of granularity in the hierarchy for synthesis.
If this capability isn’t needed, another approach is to implement this in Pinecone directly. We can include prefixes in the chunk IDs, so that one can query by prefix and get back the larger chunks as needed.
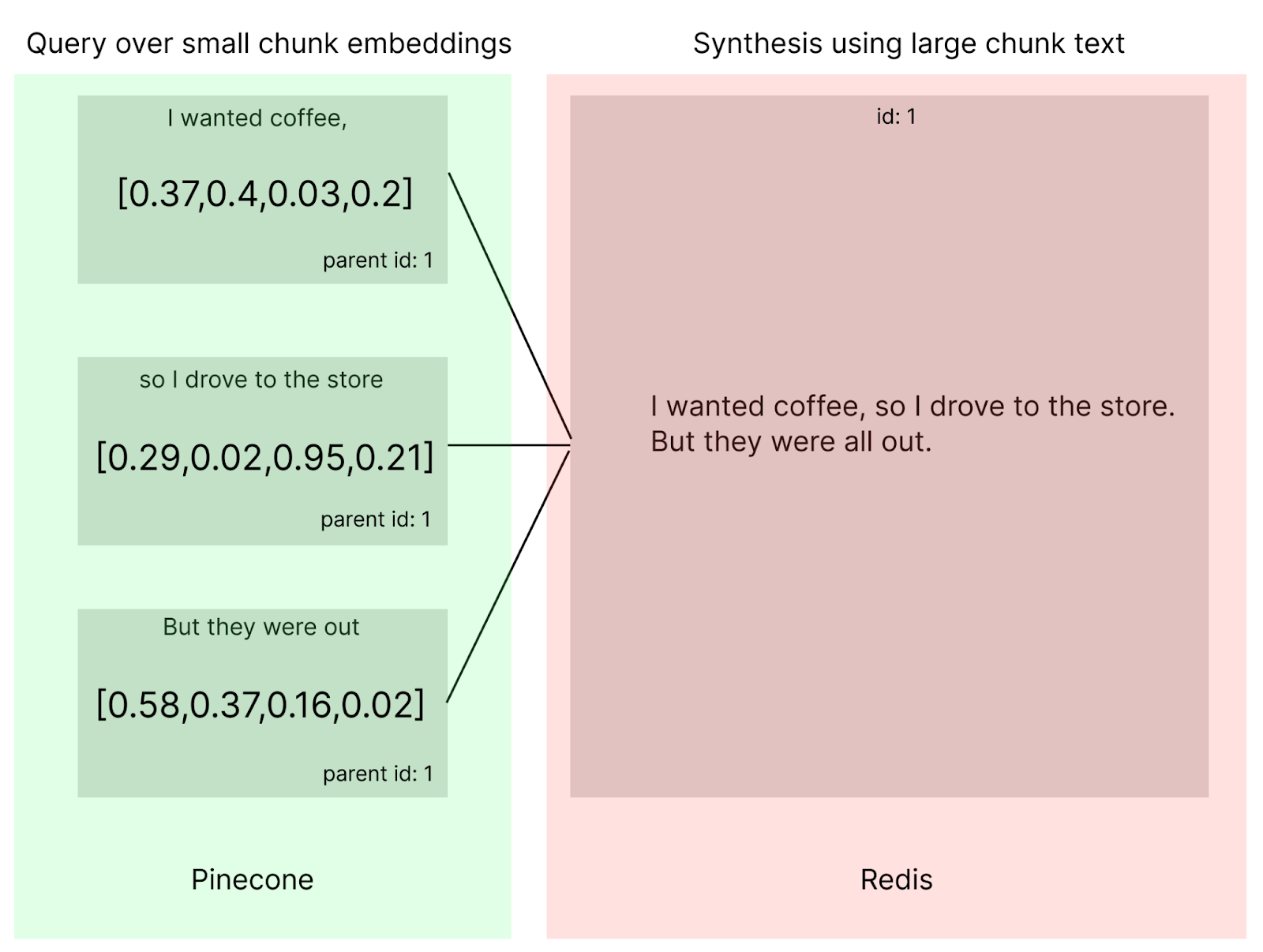
The steps above break down to:
- Break up source documents into large chunks
- Store these parent chunks in Datavolo’s doc store
- Break up parent chunks into query optimized small chunks. Each small chunk has an identifier pointing back to its parent
- Generate child embeddings from the small chunks and store them on Pinecone
To accomplish these steps, we will create a new Python custom processor that wraps LangChain’s ParentDocumentRetriever.
This is what the Datavolo data flow looks like with the new ParentDocumentRetriever custom processor:
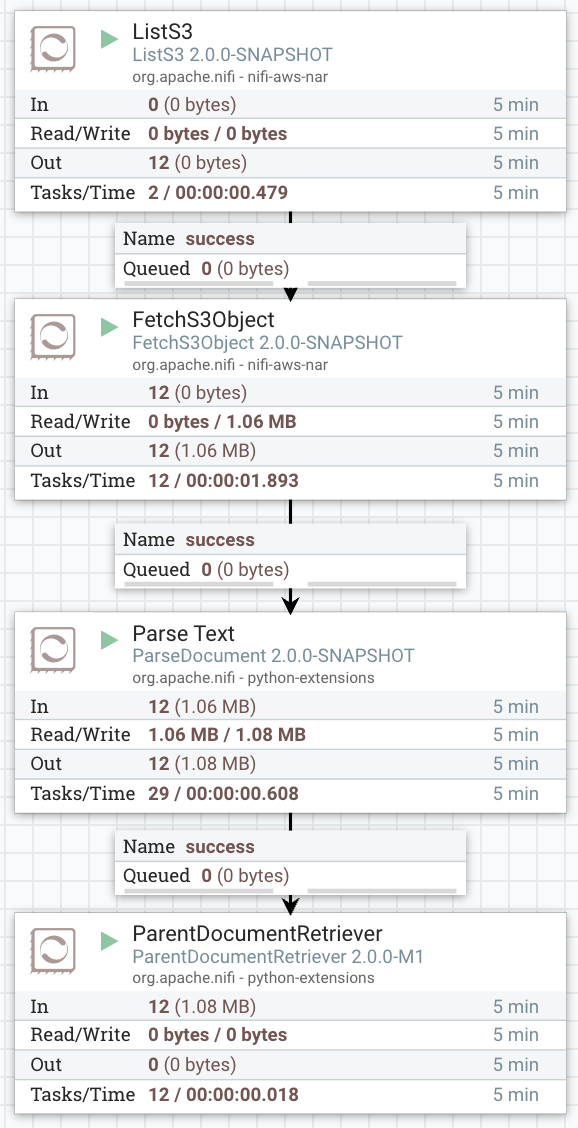
Note that the ParentDocumentRetriever processor automatically extracts the text chunks, generates their embeddings, and stores them on Pinecone. It also stores the large text chunks on Redis. This removes the need for ChunkDocument and PutPinecone processors.
Demo (Notebook)
After completing the flow and running data through we are now ready to run queries in a chat application. The following notebook provides sample code for running queries that implement the “Small-to-Big” pattern.
langchain_small_to_big_rag.ipynb
Summary
We have shown a common RAG pattern known as “Small-to-Big” which improves retrieval by using embeddings of small chunks of data, while still using larger chunks for synthesis. A powerful abstraction within the LangChain API to achieve this is the Parent Document Retriever, which is used to decouple the documents intended for synthesis from the smaller chunks used for retrieval. We leverage Pinecone’s semantic search and advanced filtering capabilities to get the most relevant context to the LLM.
Datavolo provided RAG- and AI-specific processors as well as a catalog of repeatable patterns to build multimodal data pipelines which are secure, simple, and scalable. Within this joint architecture, Datavolo and Pinecone provide all of the capabilities necessary to populate and maintain a vector store with enriched embeddings, at any scale, in a simple to use SaaS offering. Datavolo provides the capabilities to get all of your data – structured and unstructured – into Pinecone. And with the Free Tier that is offered by both Datavolo and Pinecone, you can get started for free without the need to provision or maintain any infrastructure! If you’d like to learn more, we look forward to hearing from you!