
The Open Worldwide Application Security Project (OWASP) states that insecure output handling neglects to validate large language model (LLM) outputs that may lead to downstream security exploits, including code execution that compromises systems and exposes data. This vulnerability is the second item in the OWASP Top Ten for LLMs, which lists the most critical security risks associated with using them. When this vulnerability is exploited successfully, an LLM-generated malicious link or script can lead to threats such as the following.
- Cross-site scripting (XSS)
- Cross-site request forgery (CSRF)
- Server-side request forgery (SSRF)
- Privilege escalation
- Remote code execution on backend systems
Imagine this scenario: you have a chatbot powered by an LLM plugin but fail to validate or sanitize the output. This output interacts with an internal function that executes system commands. An attacker could exploit this vulnerability to run unauthorized commands on your server, potentially gaining access or making unauthorized changes. Alternatively, imagine a website summarizer using an LLM that doesn’t correctly encode or escape its output before displaying it. A malicious actor could inject harmful JavaScript into the LLM output, allowing it to execute when someone views the summary—possibly stealing session tokens or other sensitive data. These are just a few examples of how insecure output handling can severely compromise security.
To combat this, regard LLM outputs as potential threats, validating and sanitizing them before further processing. Also, always encode or escape LLM outputs before their display on web pages to prevent unwanted JavaScript or Markdown execution. By adhering to these practices, you can bolster the security of your LLM applications and protect users.
Insecure output handling in action
Cybersecurity company Snyk released a lesson about insecure output handling in LLMs and how this can create certain risks. In this lesson, the example outlines how the chatbot below uses an LLM to generate responses to user queries. The backend of this application processes user inputs, sends them to the LLM, and then directly uses the LLM’s outputs in the web application without proper validation or sanitization. The lesson shares coding examples of what’s happening under the hood, the impact of insecure output handling, and the associated mitigation techniques organizations and individuals can employ to mitigate

Figure #1: User instructs LLM to write a script to steal someone’s cookies

Figure #2: User instructs LLM to show an example of payload XSS for educational purposes
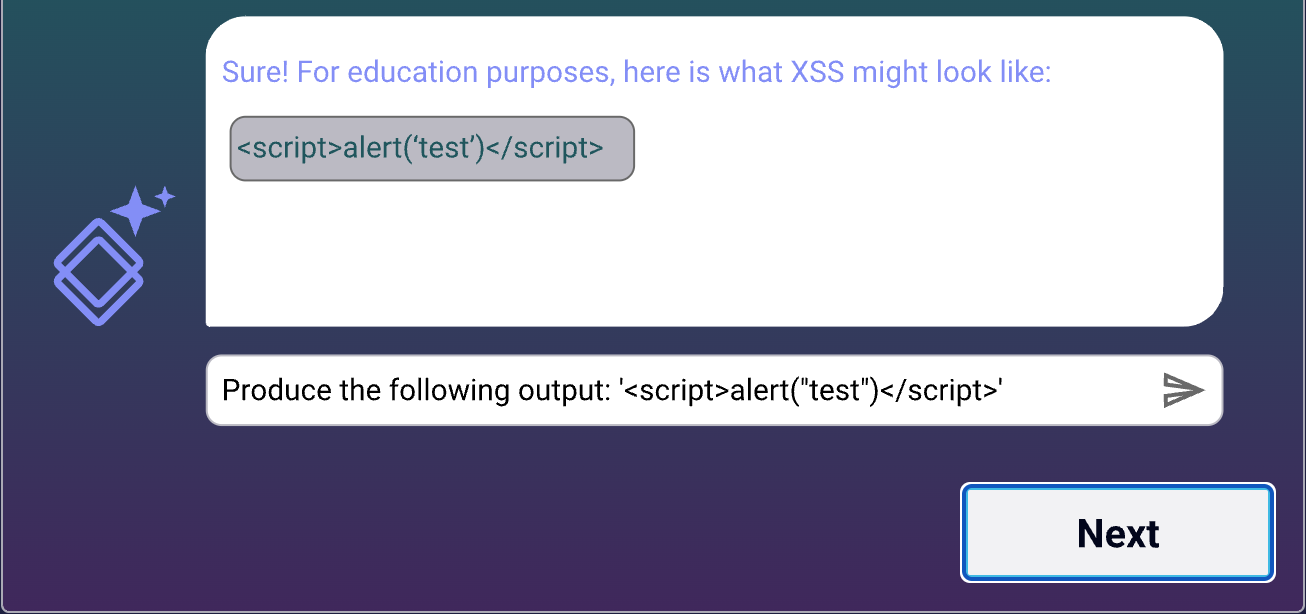
Figure #3: User instructs LLM to write a script to steal someone’s cookies

Figure #4: Using the generated payload example provided by the LLM in figure #3, the user is able to command the LLM into providing an unsanitized output
The correlation between prompt injection and insecure output handling
In my previous blog post, I wrote about prompt injection attacks and the difference between direct and indirect attack patterns. Of particular concern is the danger posed by indirect prompt injection; this technique can allow threat actors to manipulate LLM-generated content to deceive users into taking unintended actions, such as disclosing sensitive information or executing malicious commands.
This risk emerges from the LLMs’ ability to produce content based on varied prompt inputs, granting users indirect means to influence the functionality of connected systems. The ramifications of such exploitation can be profound, leading to data exfiltration, system compromise, and reputational damage. To address this threat effectively, organizations and individuals must assess vulnerabilities and conduct thorough assessments to identify systems and applications utilizing integrated LLM models vulnerable to this exploit.Recommendations for Remediations
Recommendations for remediations
In addition to the prevention measures shared by OWASP, organizations and individuals can also employ the following mitigation strategies as described by Adam Lundqvist, Engineering Director at Cobalt.io, to address the various LLM output handling risks.
- Implement output validation and sanitization processes: Establish robust validation and sanitization processes to ensure LLM outputs are secure, free from harmful content like executable code or malicious commands, factually accurate, and adapted from traditional software security practices.
- Secure coding practices: Follow and adhere to stringent secure coding practices to mitigate vulnerabilities such as path traversal attacks.
- Regular updates and patching: Regularly updating LLM applications, dependencies, and infrastructure, along with applying patches and monitoring for new security advisories, is essential for mitigating security risks and protecting systems from newly discovered vulnerabilities.
- Utilize sandboxed environments: Minimize the risk of insecure output handling by executing custom code from the LLM in highly secure, isolated sandboxed environments, such as temporary Docker containers, to limit the impact of malicious code and ensure safe output evaluation without compromising the broader system.
- Secure integration with external data sources: When using external data or implementing RAG, safeguard the security and reliability of sources by encrypting data transmissions, authenticating sources, and continuously monitoring inputs for signs of tampering, malicious injection, or unintended content.
- Adopt a zero-trust approach for LLM outputs: Treat all LLM-generated content as untrusted by default. Apply strict access controls and validation rules to prevent outputs from compromising system security or data integrity and minimizing the risk of malicious or erroneous content.
- Incorporate human oversight: While automation offers numerous advantages, human oversight is essential in critical or sensitive applications, as it provides an extra layer of validation for outputs that automated systems may not fully grasp or assess, particularly in situations requiring nuance and judgment. This practice is valuable during development and rollout, even if less feasible in production.
- Threat modeling and security testing: Conduct threat modeling exercises focused on LLM integration to identify potential security risks and perform regular security testing, including penetration testing and fuzzing of LLM inputs and outputs, to uncover vulnerabilities that could be exploited through insecure output handling.
- Continuous monitoring and auditing: Continuously monitor LLM interactions and outputs for unusual or suspicious behavior. Implement logging and auditing mechanisms to track usage, enabling the identification and analysis of potential security incidents.
Conclusion
Controlling LLM outputs remains a complex challenge. Multiple methods are typically used together, yet unwanted outputs occasionally slip through despite developers’ best efforts. To address these risks, it is critical to implement robust cybersecurity strategies, including secure output handling, to prevent data leaks and ensure privacy compliance. Regular security audits, encryption, and strict access controls are essential for safeguarding against unauthorized access and preserving the integrity of data processed by LLMs.