
The true power of chatbots is not in how much the large language model (LLM) powering it understands. It’s the ability to provide relevant, organization-specific information to the LLM so that it can provide a natural language interface to vast amounts of data.
That information can come from many different sources and in many different shapes. At Datavolo, we spend a very large amount of time communicating over Slack. We engage with each other on our own internal Slack workspace, as well as the Datavolo Community workspace. We also spend considerable time in the Apache NiFi workspace.
Some of these conversations revolve around question and answering, and troubleshooting products. This is especially true of the NiFi workspace. Other conversations center around engineering decisions. How should we address this problem? Here’s an argument for that approach, or an argument against. Unfortunately, after the conversation has ended, that context is often difficult to find. Months later, we’re sometimes left with the question, “Why did we decide not to go this route?”
This has left me wanting the ability to ask questions to an LLM about all of my conversations in Slack. And far better if the context has access not only to Slack conversations, but related content as well. For example, for troubleshooting NiFi, it would be great to have context around Slack conversations as well as NiFi’s official documentation and even community blog posts, Jira tickets, and mailing lists. For engineering discussions, it would be great to have the additional context of design documents.
So I set down the path of feeding slack conversations into Pinecone. Using NiFi, naturally.
The Naive Approach
The first approach that we considered for harnessing the information in Slack was to simply pull data directly from Slack using NiFi’s ConsumeSlack processor, creating embeddings for the slack message, and feeding that into Pinecone.
To test, we created a channel and some conversations just to simply test the feasibility. The results were surprisingly good! Mission accomplished.
But the excitement was short-lived. Turning it to “real conversations” – not those that were short, canned conversations, yielded far worse results.
The Curveball
It didn’t take long to realize the reason for the disparity. Our canned conversations contained paragraphs or several sentences in each message. That is, the messages in our canned conversations were long enough to provide sufficient context. Real Slack messages, especially between those who know each other well enough to relinquish formality, tend to be made up of several short messages.
To make matters worse, depending on those in the conversation and the particular channel, some conversations take place in threads, while others take place in the channel itself. Both are common and valid forms of communication, and they’re even sometimes mixed.
The Solution
When we create embeddings for a given Slack message, we need the ability to provide enough Slack messages that the embeddings we create have relevant semantic meaning. To do this, we decided to push the messages first to a Postgres database. Then, for each message, we would query the database to enrich the message. If the message is in a thread, we grab the 4 messages prior in the same thread, as well as the first message in the thread, which typically asks as a “title” for the conversation. For messages that are not part of a thread, we grab the prior several messages in the same channel that are not threaded.
Fortunately, NiFi makes this work child’s play. Inserting a simple PutDatabaseRecord processor gives us the ability to push all of the messages into the database. On the enrichment side, we use a ForkEnrichment/JoinEnrichment along with an ExecuteSQL. This gets us 90% of the way there.
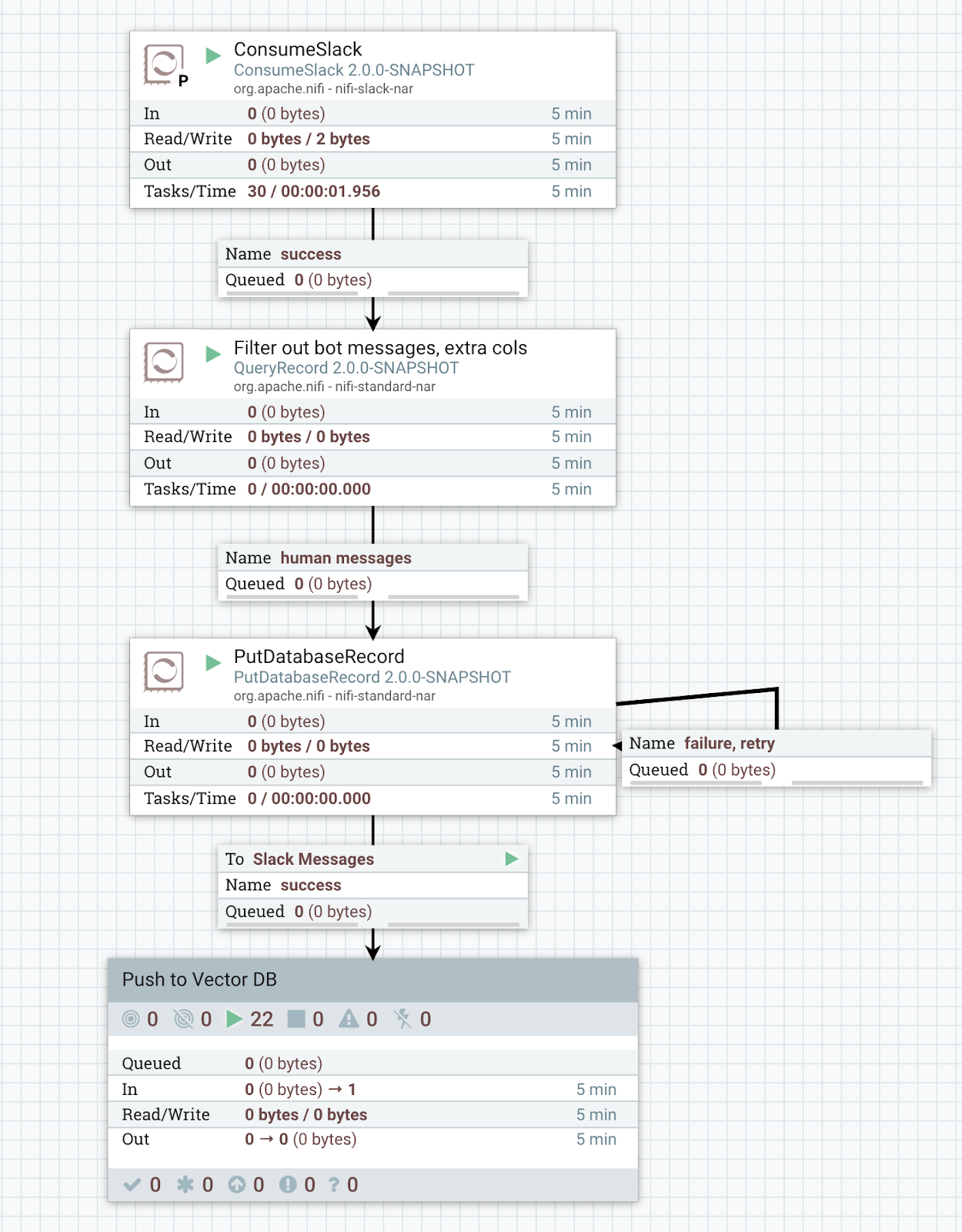
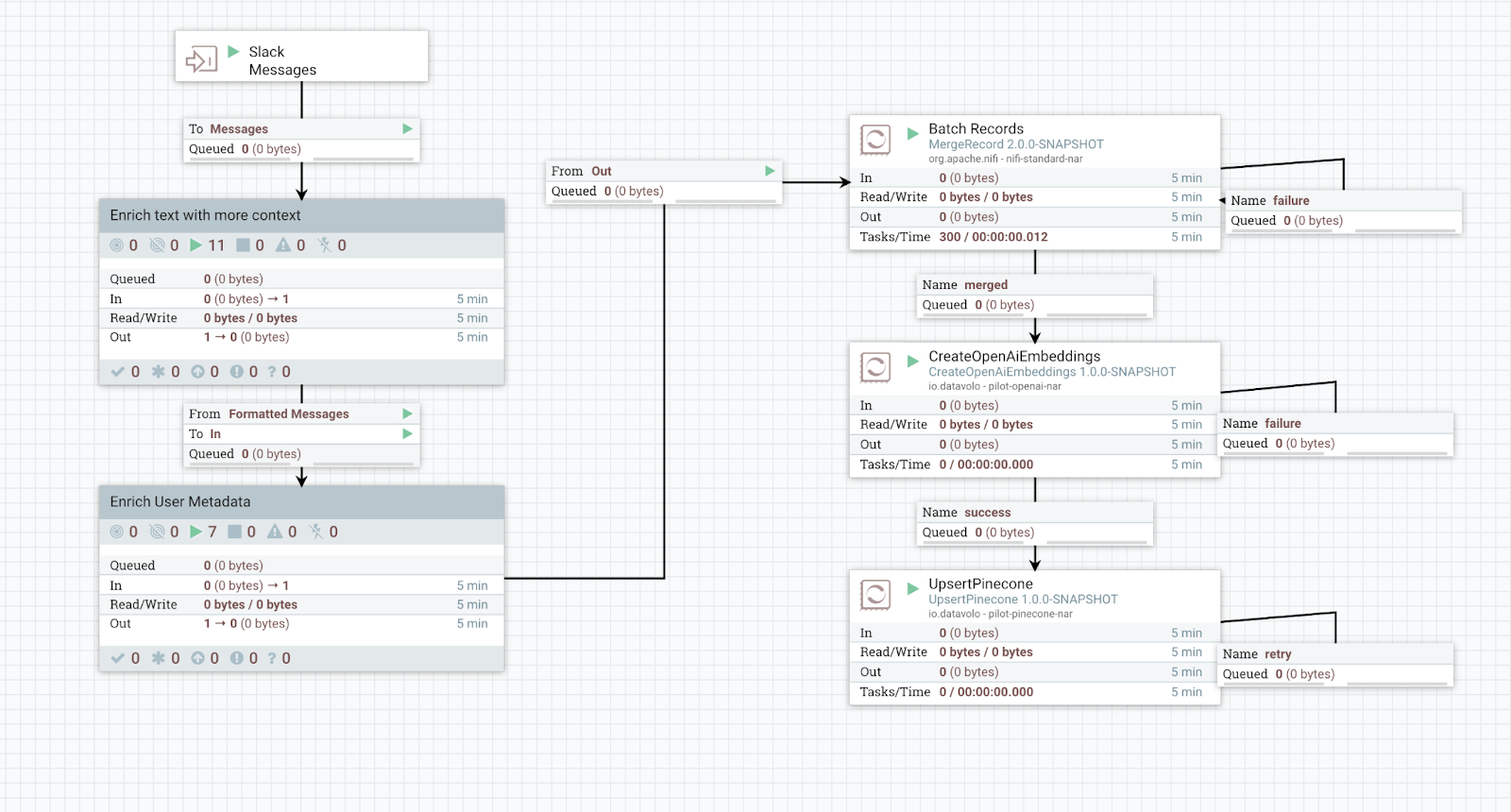
The complexity comes in formatting the message in a way that semantic meaning can be easily encoded with an embedding. Studies and experience have shown that using JSON results in less-than-ideal retrieval. Fortunately, with NiFi 2.0, we can simply create a custom Processor using Python. In about 12 lines of Python, we’re able to convert the messages into a conversation that looks something like:
John: Can Datavolo help me to make Slack messages searchable by our LLM?
Jane: Absolutely! ConsumeSlack -> PutDatabaseRecord -> Enrichment -> Pinecone. Easy peasy!
The Result
An easy way to test the effectiveness of our approach is to create a simple Slack Bot that allows us to ask questions directly in Slack and have the bot make use of our Pinecone index, making use of OpenAI and Langchain. NiFi’s QueryPinecone and PromptChatGPT Processors do just that. We found that this approach provides impressive results!
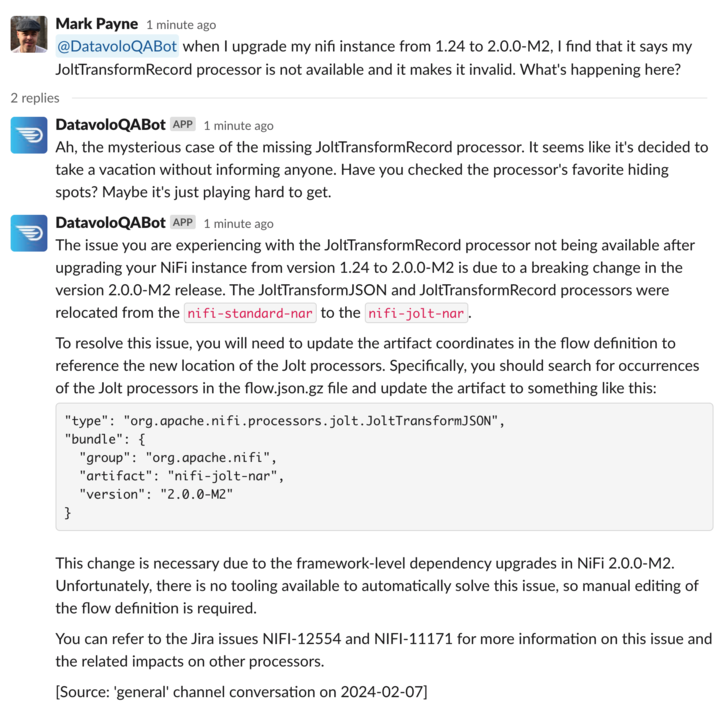
If I ask it for a bit more context about when that conversation took place:


The Bonus
We can now gather all of the Slack messages that we care about, create embeddings with relevant semantic meaning, and push the results into Pinecone. On the front end, we can query those using custom code, LlamaIndex, LangChain, or any other framework we care to use.
A nice benefit of NiFi, though, is that we can easily provide enrichment to our data. We can, for instance, easily add the users, message timestamps, threads, channels, and more, to the Pinecone metadata. This allows our front-end to use Pinecone filters to easily control what is returned. Or to get Slack’s message.ts field in order to create a URL to the actual Slack conversation. Or simply provide the metadata to the LLM, so that when users ask questions, they can ask where the provided information comes from.
And we can leverage NiFi’s Provenance capabilities to understand the data’s full lineage. Where the data came from (whether Slack, a design document in Google Docs, official NiFi documents from the website, or a blog post). We can also understand exactly how the data was transformed every step of the way.
Of course, with hundreds of connectors out of the box, onboarding additional sources of information for our chatbot to use is simple as well!
The Connection
Datavolo is committed to providing the best service possible, to help you quickly and easily supply your structured and unstructured data to your Generative AI models. If you’d like to learn more, we look forward to hearing from you!