")
Digging into new AI models is one of the most exciting parts of my job here at Datavolo. However, having a new toy to play with can easily be overshadowed by the large assortment of issues that come up when you’re moving your code from your laptop to a production environment. Similar to adding a new dependency to your code base, adding a new AI model brings with it its own set of transitive dependencies, which can expose you to new security, performance, and portability issues. In the following, we’ll discuss how preferring the ONNX® (Open Neural Network eXchange) format has helped Datavolo mitigate many of these issues in our AI applications.
Why ONNX?
PyTorch, TensorFlow lite, ONNX, Safetensor, and many others are all open serialization formats for saving and loading trained model data to and from disk. Similar to how you might decide between Jackson and GSON to process your JSON data, choosing the right AI model runtime can be consequential for your application on many levels. For example, before we consider bringing in any library for any reason we need to assess the security risk. Only after that can we consider the runtime’s actual functionality. For functionality, we’re looking for 3 things: can it execute my models, how quickly do those models run, and does it run on my hardware in the language of my choice? ONNX checks all those boxes.
Security
Unlike Jackson and GSON, AI model runtimes tend to come with a long list of transitive dependencies. While having dependencies does allow open source maintainers to avoid duplicating code for previously solved problems, it also makes their projects vulnerable to security, performance, and compatibility issues in those libraries. Let’s look at an image scan of the base Pytorch image in DockerHub:
grype pytorch/pytorch -o sarif > pytorch.sarif
✔ Vulnerability DB [no update available]
✔ Pulled image
✔ Loaded image pytorch/pytorch:latest
✔ Parsed image sha256:bbb9480407512d12387d74a66e1d804802d1227898051afa108a2796e2a94189
✔ Cataloged contents 11691e035a3651d25a87116b4f6adc113a27a29d8f5a6a583f8569e0ee5ff897
├── ✔ Packages [222 packages]
├── ✔ File digests [3,768 files]
├── ✔ File metadata [3,768 locations]
└── ✔ Executables [1,341 executables]
✔ Scanned for vulnerabilities [94 vulnerability matches]
├── by severity: 0 critical, 30 high, 256 medium, 76 low, 19 negligible (3 unknown)
└── by status: 198 fixed, 186 not-fixed, 290 ignored
The example reveals several issues. First, the overall size of the image is over 3 GB. While storage costs are generally cheap, image size can impact the performance of scale-ups in a container environment. This also generally indicates a second problem, which is that the things taking up space are generally additional code that may or may not be used in your application, but may have security vulnerabilities that you’ll need to track. More dependencies mean a larger attack surface for hackers. Now compare this image to the base Ubuntu image with Python and the ONNX runtime installed during the image build process:
grype localhost/datavolo-io/table-structure-recognition-service:latest -o sarif > table.sarif
✔ Vulnerability DB [no update available]
✔ Loaded image localhost/datavolo-io/table-structure-recognition-service:latest
✔ Parsed image sha256:697057db87a9819eaac2e69f117170c469e0559b5f5c9a7a603eb903f4fe7f84
✔ Cataloged contents 3069ea21735b6f473626592bd8731f71e9df52f6248ffad5019c6331836c4a1d
├── ✔ Packages [170 packages]
├── ✔ File digests [3,704 files]
├── ✔ File metadata [3,704 locations]
└── ✔ Executables [881 executables]
✔ Scanned for vulnerabilities [22 vulnerability matches]
├── by severity: 0 critical, 0 high, 10 medium, 10 low, 2 negligible
└── by status: 8 fixed, 14 not-fixed, 0 ignored
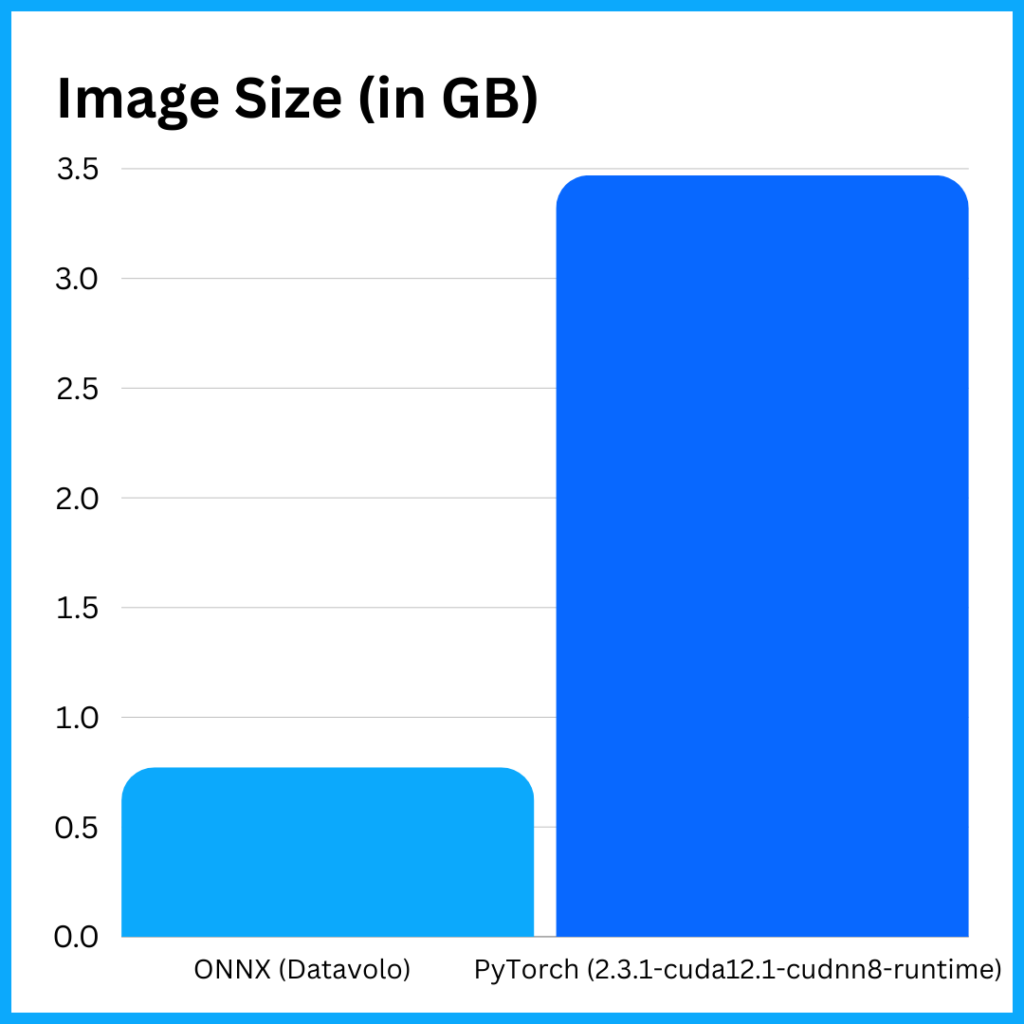
Less packages, fewer executables, and the image is under 1 GB. A dramatic decrease in vulnerability due to a decrease in the attack surface. Faster scale-ups since the image takes less time to download over the network. So, it is more secure with less space.
Functionality and Performance
Now how can ONNX be so much smaller? It’s not magic. ONNX is optimized to be a runtime. So it’s good at running inference on your AI models. While ONNX does have some support for training models, when you look around GitHub libraries like Pytorch and Tensorflow, they dominate the code repos that are used to design and train AI models. But why bring all those fancy training tools and libraries with you if all you want to do is run the model in prod? Don’t. Instead, evaluate what you want to use for a runtime separately from what you use to train.
While currently many models are not originally trained on the ONNX runtime, there are several converters available to convert models from Pytorch, TensorFlow, and Safetensors to name a few. There are many pre-converted models of popular libraries available in the model zoo. Our experience with converting models below 1GB has been very successful with both YOLOX and Microsoft’s TATR model, which we use to detect document and table layouts respectively. In both cases, the model was faster than the Pytorch or Safetensor version.
YOLOX (Pytorch)
Unset
(.env) bpaulin@Bob-Ubuntu:~/git/YOLOX$ python3 tools/demo.py image -f yolox_layouts.py -c best_ckpt.pth --path /home/bpaulin/git/YOLOX/DocLayNet_core/PNG/0a0bf17f97a0d6c5c4a19e143faf58235a54e56ad19c447c32cd7ba3b59e51fb.png --conf 0.3 --tsize 1024
2024-06-06 15:00:40.244 | INFO | __main__:inference:165 - Infer time: 0.9732s
/
YOLOX (ONNX)
(.env) bpaulin@Bob-Ubuntu:~/git/YOLOX$ python3 demo/ONNXRuntime/onnx_inference.py -m yolox_m_layout.onnx -i /home/bpaulin/git/YOLOX/DocLayNet_core/PNG/0a0bf17f97a0d6c5c4a19e143faf58235a54e56ad19c447c32cd7ba3b59e51fb.png -o test_onnx -s 0.3 --input_shape 1024,1024
2024-06-06 15:00:15.678 | INFO | __main__:<module>:70 - Infer time: 0.3462s
Inference Time in Seconds
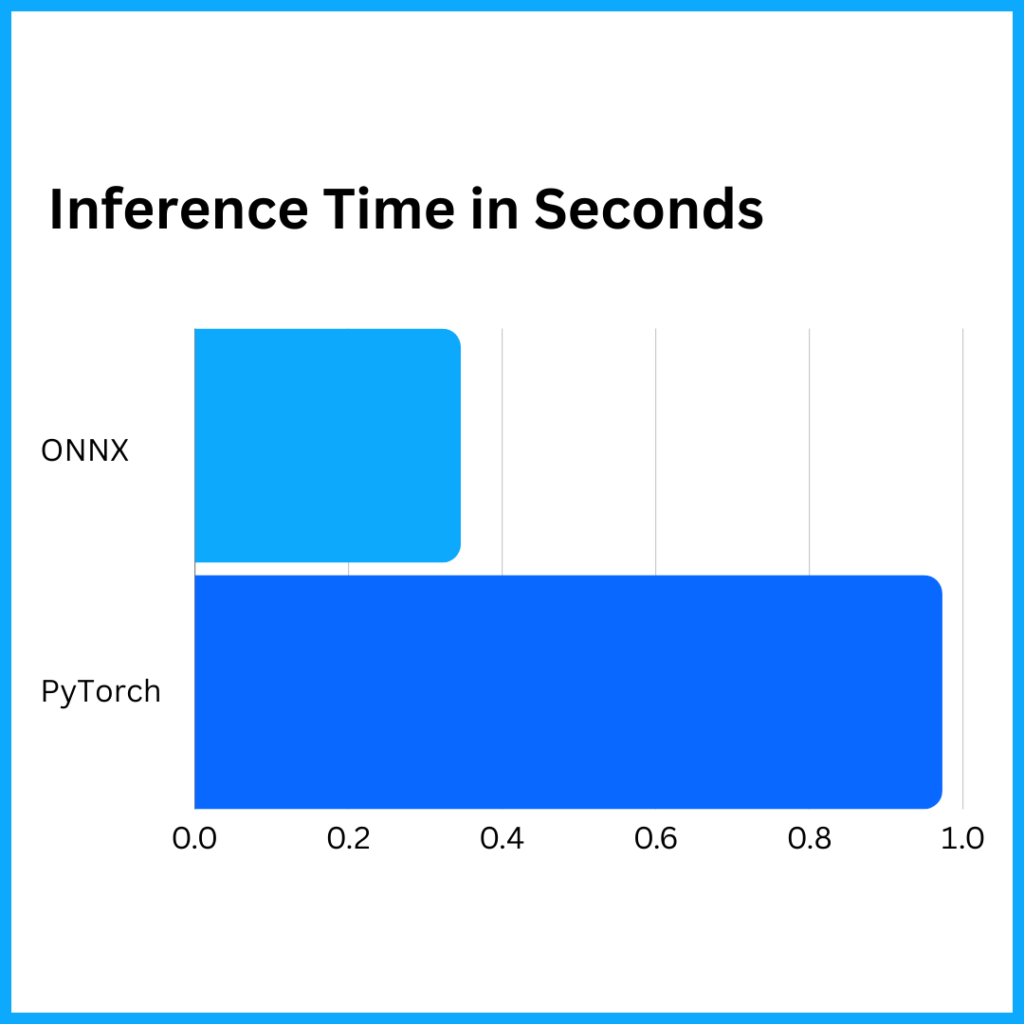
Both of the above examples were run without GPUs on an Apple MacBook Pro with an M3 Max arm64 chipset and 48GB of RAM. We’re not talking about running it on an average PC, but we are talking about a 3x speed-up on the same hardware. If you were running inference at scale a 3x performance improvement adds up quickly in cloud costs and/or your application SLA.
Cross Platform Compatibility
Finally, ONNX has broad support across language and hardware runtimes. The AI eco-system is very heavily slanted to Python and the whole diversity is found on the hardware side where support for GPU/CPU (amd64 and arm64) is the standard. ONNX support goes across a second dimension that is less popular with model runtimes, and language runtimes, with support that includes Python, Java, C, C++, and C#. ONNX also has a broad range of supported OS and hardware compatibility to go along with this.
Onward with Datavolo
At Datavolo, we’re very big on Apache NiFi which can save you from writing lots of insecure custom code for your AI data pipelines. In Datavolo’s environment, ONNX’s portability provides our services significant flexibility to run the models embedded in a NiFi Processor or a language-specific microservice. If you’d like to learn more about some of our ONNX models, ask for a demo! Or work with the models yourself by following our tutorial for converting a model to ONNX.