
New support for writing to Apache Polaris-managed Apache Iceberg tables enables Datavolo customers to stream transformed data from nearly any source system into Iceberg. Originally created by Snowflake, Polaris allows customers to use any query engine to access the data wherever it lives. These engines leverage Polaris via the REST interface. In addition to the obvious choice of Snowflake, other query engine examples include Spark and Trino. And because Polaris is based on Iceberg’s REST specification, its introduction creates new possibilities for architectures developed in languages other than Java.
At Datavolo, we are focused on solving data movement problems for the largest workloads. Polaris-managed Iceberg is increasingly a target for enterprise data and we believe it will supersede other Iceberg metastore implementations based on Hive and Hadoop. Read on for more about how Datavolo support streaming data to Iceberg.
Datavolo’s Implementation
To support Iceberg, we added a new processor and two controller services to Datavolo runtimes:
- The PutIcebergTable processor handles writing data to an Iceberg table within a namespace. This processor differs from the OSS NiFi processor PutIceberg which does not currently support integration with Polaris or REST Iceberg Catalogs.
- The PolarisIcebergCatalog controller service is used by the processor to land records in the correct cloud storage environment.
- The ParquetIcebergWriter controller service handles chunking large files and automatic conversion to Parquet.
Polaris Catalog integration
The Datavolo PutIcebergTable processor appends rows to an Iceberg Table within a namespace. To do so, it needs to authenticate to both the configured Polaris Catalog and to the backing object storage service.
Datavolo’s PolarisIcebergCatalog controller service handles this authentication and has first-class support for Polaris catalogs like Snowflake’s Polaris and for S3-backed storage. We are investigating compatibility with other REST Iceberg catalog implementations and plan to extend support to stream data to Iceberg tables backed by Google Cloud Storage and Azure Storage. We welcome feedback on which catalogs and storage services you would like to see us support—drop us a line!
Batching files for better performance
Apache Iceberg recommends batching records into 512 MB Parquet files for optimal query performance. Datavolo supports a number of strategies to optimize for different needs.
As part of converting to the Parquet file format, our ParquetIcebergWriter will split large Flowfiles into separate files of a configurable size, defaulting to 512 MB.
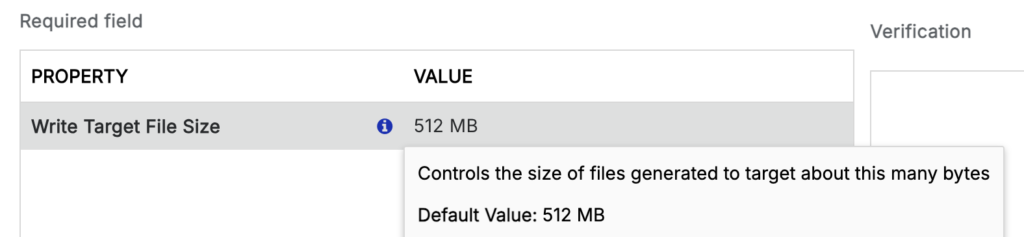
If ingestion to Iceberg is based on data streams that do not produce such large sets of records, or if batch file sizes are not this large, users have several options. Flowfiles representing smaller batches of records can be passed immediately through to Iceberg, where users can compact them later with downstream query engines if needed.
In cases where it is not necessary that data land in Iceberg as quickly as possible, the MergeRecord processor comes in handy. MergeRecord lets users assemble larger Flowfiles and has several relevant parameters. For example, setting the maximum bin age to 10 minutes will ensure that all records are held in this stage for no more than 10 minutes. Maximum bin size can be used to set a target file size before conversion to parquet.
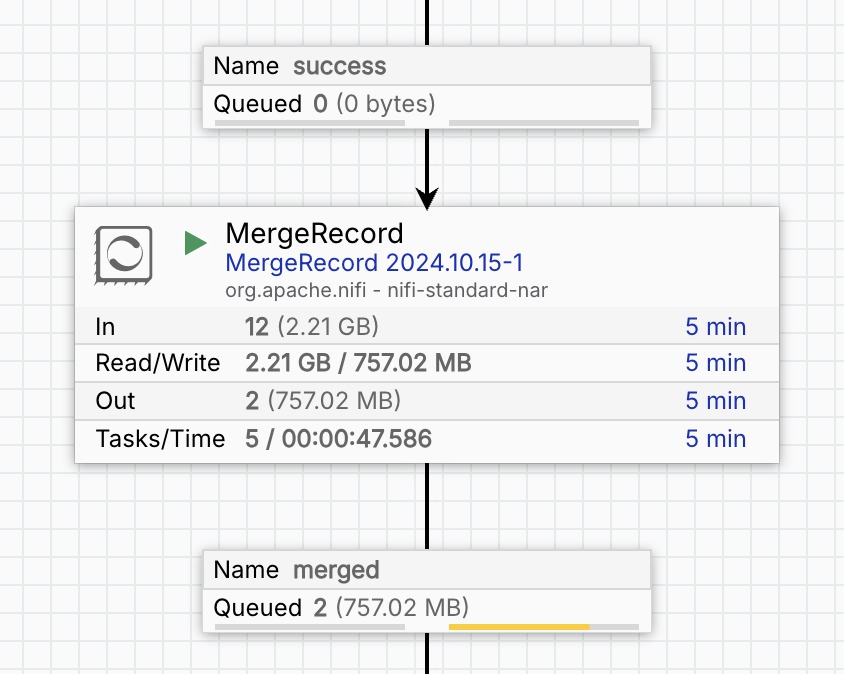
Users should keep in mind that the file formats being merged are usually not as compact as Apache Parquet and the MergeRecord’s max size should be higher than the PutIcebergTable’s target file size.
Parquet formatting
Datavolo makes it simple to deal with any data format, and writing data to Iceberg is no exception.

The ParquetIcebergWriter service will automatically convert any supported record type—including CSV, Avro, JSON, and XML—to Parquet, allowing users to focus on their pipeline and not on data engineering drudgery. For unstructured source data like PDFs and Excel spreadsheets, Datavolo provides a suite of converters and parsers to extract structured data prior to insertion into Iceberg.
Demonstration
In the following demonstration video, many of the concepts above will be discussed. The demo is retrieving CSV data files with approximately 110,000 records each and consumes about 180 MB of space. These records need to be loaded into an Iceberg table with the same schema as the data file already has.
Initially, the demo shows that each of these 180 MB files are converted to Parquet and then loaded into the AWS S3 bucket backing the table. These records encode and compress very well with Parquet and end up being < 5 MB in size.
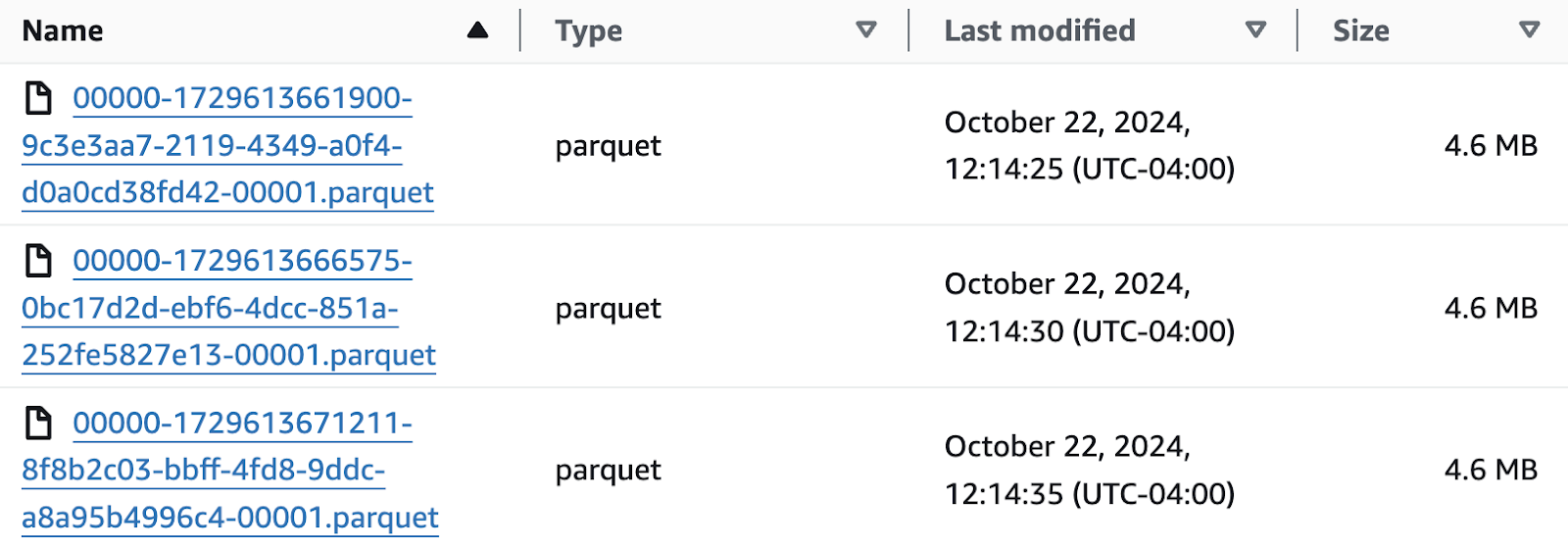
While these file sizes are not optimal by any measure, the data is available for data analytics immediately. The demo explains that the default setting of 512 MB being used only works when the inbound file, once converted to Parquet, exceeds that amount. When the converted Parquet data is under the configuration value, the processor persists it regardless of size.
The video shows an example of using the MergeRecord processor to concatenate together multiple input files into fewer, but larger-sized, ones. In the scenario show below the files are still smaller than desired, but this simple example is still useful as there will be ⅕ of the number of files and each will be 5x the size as before.
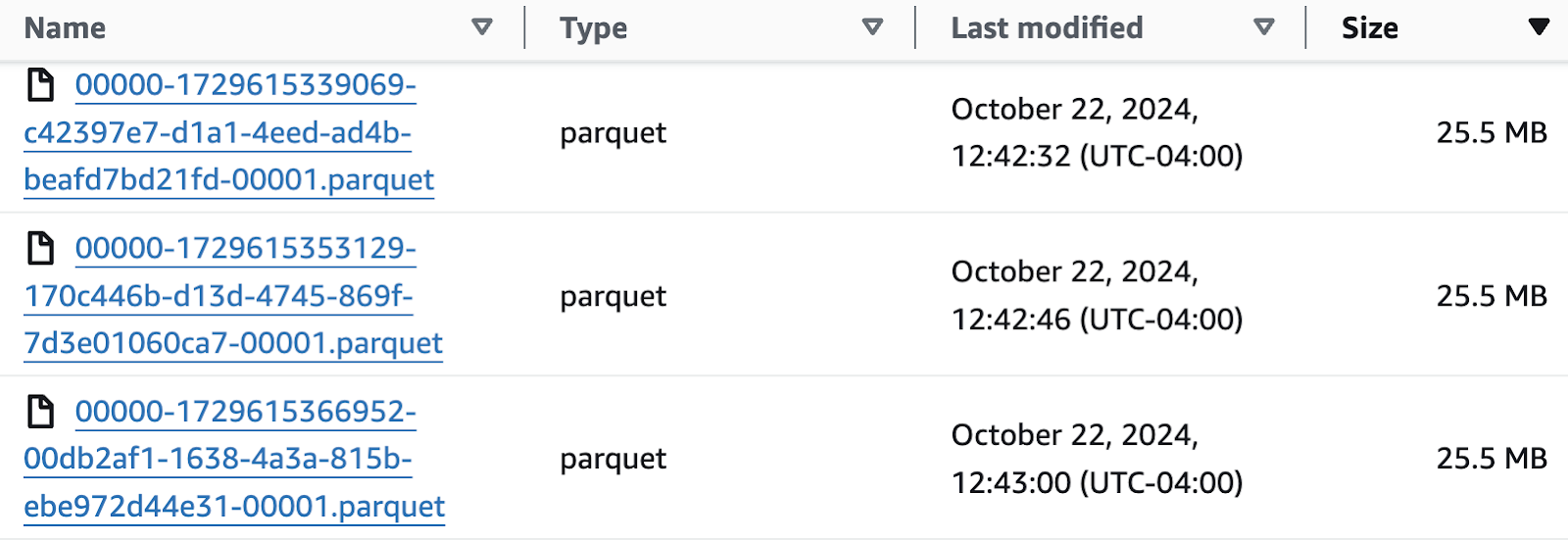
Finally, the demonstration indicates that all Apache Iceberg tables will still need some regular maintenance that will include periodic “compaction” tasks. That task simply rewrites any of the underlying files that are too small into fewer, larger ones.
Conclusion
At Datavolo, we specialize in solving business-critical data movement problems securely and efficiently. With new integrations for Apache Polaris and Apache Iceberg, organizations can populate Iceberg tables with streamed, multimodal data in almost any format and from any source system. Together, Datavolo, Polaris, and Iceberg help companies future-proof their data strategy by reducing query engine lock-in and maintaining control over their data at rest. Please reach out to us to learn how we can advance your data strategy.