
Survey of long time users to understand NiFi usage
Datavolo empowers and enables the 10X Data Engineer. Today’s 10X Data Engineer has to know about and tame unstructured and multi-modal data. Our core technology, Apache NiFi, has nearly 18 years of development, operations, and an open source community nearing its 10 year anniversary. We’ll unpack a bit more of the history in the next couple sections. It is vital to learn from the existing user base so we conducted a survey. We focused on users that have been through the learning curve, know what works, and have seen diverse use cases. The survey results give us a clear roadmap to drive more value for our users!
In June 2024 Datavolo conducted a survey and what we learned follows. First let’s recall some history for how NiFi has evolved.
NiFi is made for Unstructured and Multimodal Data
The U.S. National Security Agency (NSA) released Apache NiFi through a Federal technology transfer program (NSA TTP) in 2014. During the ‘NSA years’ NiFi gathered, processed, and delivered unstructured and multi-modal data distribution at massive scale. In 2015 NiFi was first commercialized by Onyara which was acquired by Hortonworks which later merged with Cloudera in 2019. During the ‘Hadoop years’ NiFi was key technology for massive scale ingest of structured data to Hadoop clusters.
Throughout that time NiFi adoption has grown to more than 8,000 global enterprises according to open source information. The primary user base for NiFi are Data Engineers and broader IT professionals. The user experience supports both code centric developers and those who benefit from a low-code and powerful visual user experience.
We Must Improve The Data Engineer and Unstructured Data Experience
In the second half of 2023, a couple of things came into focus and motivated the founding of Datavolo.
First, it is clear we can do far better for the Data Engineering community. Support for true Python developed extensions is critical.
Second, as we move from the structured data dominated enterprise into the Generative AI world unstructured data becomes paramount. Unstructured and multi-modal data use cases differ in some important ways but do follow familiar patterns with structured data. For the enterprise the pattern is change data capture, transformation, and delivery. Change data capture means monitoring and replicating content and metadata changes from places like Google Drive and Microsoft Sharepoint. Transformation means converting documents, audio, video, and images into structured representations with narrative text. Delivery means driving these structured forms into Snowflake, Databricks, and Cloud Service Provider services or to Vector stores having chunks and embeddings established.
Findings From a Targeted Survey of Long-Term Users
What follows are some of the conclusions we can draw from this initial survey. We are grateful to all those who participated! We will create a broader user base survey at a later time for those that could not participate this time.
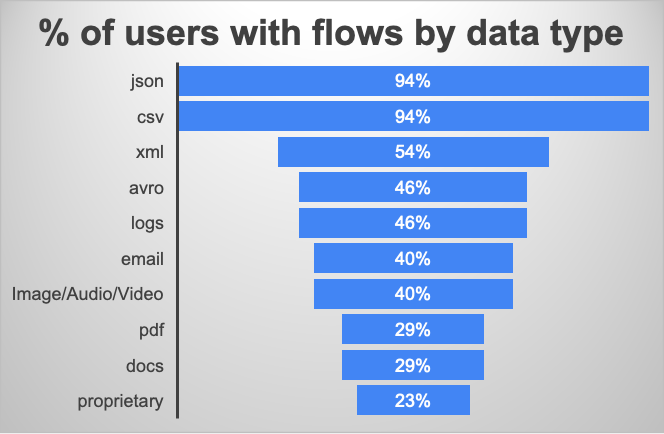
What Type of Data is NiFi Used For
Over 90% of all NiFi users leverage it to handle JSON and CSV data. More than 50% of users handle XML data but there is a clear decline of XML in recent releases. The same can be said of Avro with 40% of respondents using it though usage declines in recent releases. Protobuf meanwhile is emerging as an important format for NiFi 2.x users.
Many users already utilize NiFi for unstructured data capture, transformation, and delivery. This is increasingly true for users with large flows and who have built custom extensions. This tells us that the users come for structured data handling from databases or logs – but stay and graduate to unstructured data! For image, audio, and video data 40% of the users rely on NiFi and the ratio increases with newer releases. 23% of users handle their companies’ custom and proprietary data formats.
What Type Of Use Cases is NiFi Used For
Observability: 50% of users rely on NiFi for data involving observability and techops data collection, filtering and enrichment. The data is then delivered to Splunk, ElasticSearch, and others.
ETL and ELT: A quarter of the users build NiFi flows to handle ETL or ELT flows. ETL cases for NiFi are pulling from a database, preparation, and data delivery to another database or warehouse. ELT cases rely on NiFi to orchestrate ingest to a data lake and initiation of processing jobs in Spark or others.
Data Integration / Data Distribution: More than 40% of the users leverage NiFi for large-scale enterprise data integration or data distribution needs. Here NiFi serves as a general purpose data router. The IT or data analyst configured NiFi for which protocol to use to grab, transform, and deliver data downstream.
Unstructured Data: More than 30% report they’re already using or planning to use NiFi for unstructured data use cases. These scenarios fuel AI applications or integrate machine learning functions in-line in the NiFi flow. Notably some respondents highlighted not realizing NiFi could handle such data or use cases.
What Roles and Personas Use NiFi And How is it Changing
More than 80% of NiFi users identify as software developers with their primary language being Python or Java. Python was possible but difficult to use in NiFi until 2024. And despite this 50% of those identifying as developers were Python developers. Interestingly of those developers now using the latest NiFi (2.x) 80% are Python first!
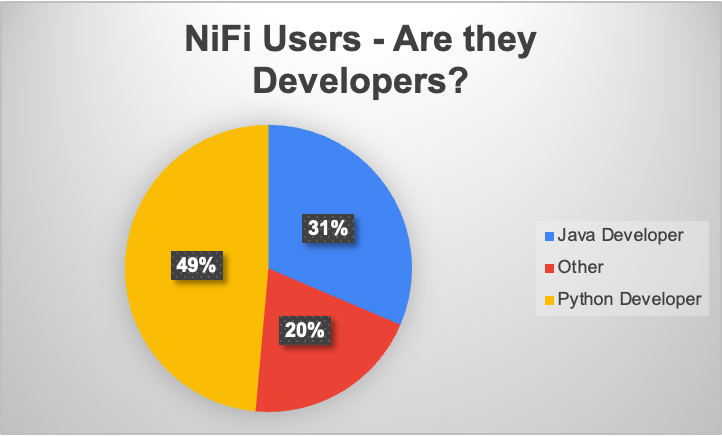
50% identify as ‘Data Engineers’ and nearly 30% are general software engineers or cybersecurity engineers. The remainder are general support specialists, consultants, or enterprise architects.
Survey Questions to Learn More About Likes and Dislikes for NiFi
We also asked a set of open ended questions in the survey. Specifically we sought input on what was most loved and needed most improvement.
Survey highlighted strengths of NiFi
Building flows in NiFi is so fast and easy
This was overwhelmingly the most popular theme of input. Users love the user experience and flexibility to create powerful flows across diverse use cases. Users found it powerful they could handle use cases previously described and also create API endpoints or a web services.
Great choice of out of the box components with proven enterprise ready patterns
NiFi makes it easy to get data in and out of databases, Kafka, and many other systems. Data transformation which is both format and schema aware is easy and performant with record oriented components. And when something isn’t already there NiFi is designed for extension.
NiFi enables vendor neutrality
With NiFi you can easily capture data from any system and you can deliver to any system. This puts you in control of your data pipelines and data architecture. Far too common these days is a given platform provides an ‘ingest tool’ but it only ingests to that one platform. You need to be in control of your pipelines and NiFi gives you this freedom. This is critical today with GenAI where for instance NiFi can easily send to any vector store or data platform. NiFi could also easily interface with any LLM provider or embedding model.
True Python Extensibility
NiFi has always enjoyed a well defined and proven API for Java developers to build extensions. But if we are being honest with ourselves the largest base of Data Engineers skew strongly toward Python. The community is nearing a full General Availability release of NiFi 2.0. For now the milestone releases are seeing significant adoption and as already mentioned many of these are Python developers. That is because in NiFi 2.0 we have introduced a pure Python based extension model. This new model unlocks a large new developer base for NiFi. Critically, Python affords a rich and amazing ecosystem of ML and AI components and libraries to leverage which can now happen easily in NiFi.
NiFi flows are fast, resilient, scalable and reliable
Flows in NiFi generally are very fast. It is common for flows to handle hundreds of thousands if not millions of events per second. Similarly flows running at rates of 100s of MB/sec up to GB/sec of throughput are common. We’ve also observed flows in large enterprise settings with 10s of thousands of NiFi processors running simultaneously. Importantly though NiFi is still easy to use when your data rates aren’t as impressive or sustained.
NiFi also provides for strong built-in error handling – essential for orchestration and data integration requirements. Data durability was always strong in NiFi but availability could suffer in the event of a node outage. Recent Kubernetes based deployments of NiFi and general Cloud Native deployment practices have eliminated this problem. The powerful built-in congestion control and back pressure are vital to handling common scenarios. Congestion control is essential at scale due to surges in new data, some transforms can be quite compute or IO intensive, and downstream systems can be off-line or sluggish.
Flows in NiFi are highly observable and explainable
NiFi generates fine grained data lineage for every piece of data going through it, enabling detailed troubleshooting and replay. The logs are easily accessible and exported and both push and pull based mechanisms exist providing access to its myriad metrics and measures for systems or protocols like ElasticSearch, Open Telemetry, Grafana, and Prometheus. Flows are visually intelligible and interactive which means it’s easy to know how a flow works and to make changes.
Survey Identified Areas Where NiFi Needs To Improve
More unstructured transformation options
Use cases to capture documents such as Word, Excel and PDF and transform them into fully structured representations are increasing. While we’ve converted these documents into formats like CSV in the past, a more rich and hierarchically faithful representation of such documents which can include images, charts, and tables is required.
Improve the user experience for handling and manipulating JSON
JSON is the dominant type of data across NiFi flows. The user experience offered to manipulate JSON forces users to do a lot of custom coding. The Jolt based transforms are hard to use with limited documentation. We need to provide a more visual way of taking a given JSON input and structure and converting it to a given output structure.
The user experience for NiFi is due for a refresh and an evolution.
For the user experience of NiFi the following improvements are often requested:
- Offer a Dark Mode (NiFi is present in many operations centers where dark mode is key)
- Provide keyboard shortcuts to get to certain processors faster
- Refresh the look of the UI and use modern Javascript frameworks and themes
- Improve the user experience for error handling in flows
- Support undo (CTRL-Z) !
- Provide a locked-down or frozen flow mode so accidental changes cannot be made
Improve NiFi alignment with SDLC best practices
NIFi needs better integration with common SDLC practices for DevOps or GitOps. While the mock framework enables unit testing of components users have long wanted a way to create unit tests of full flows. This is important to improve automated testing and promotion from dev to production. The process for authoring new components in Python needs to better documented with more examples. The documentation must show how Python components can be built and tested with popular Python tooling. Python developed components should also have a clear and secure path to production. Versioned flows are excellent but users want an ability to visualize differences and perform merges.
A cloud native and well supported offering for NiFi is required
Users want an easier path to operate NiFi clusters in Kubernetes with elastic scaling. NiFi should easily integrate with popular secret stores and OIDC providers. Upgrades, including rolling, should cleanly handle moving from one NiFi version to another. Users across AWS, GCP, Azure, OCI and OpenShift want fully integrated and supported offering for NiFi. Users want a fully supported offering for delivering unstructured data to hyper scale data platforms such as Snowflake and Databricks.
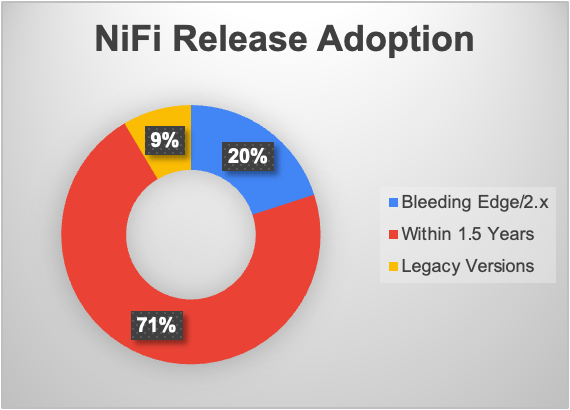
Users update and keep NiFi recent with 20% already on the pre-release NiFi 2.x line and more than 70% running on releases within the past year and a half.
Use Case and Solution Oriented Blogs and Documentation
It remains difficult for users to find strong canonical examples of flows that already work. Users want a much better demonstrated path from idea to production. They need more prescriptive documentation and help deploying ‘on prem’ and in the cloud. Vendor support to harden the journey to production and be available in the event of trouble is a gap. The Generative AI movement and the associated need for unstructured data ingest has made these all the more pressing. And as noted previously some users do not even realize NiFi is perfectly suited to this unstructured data task.
Summary of Survey Findings and Next Steps
The survey findings are valuable to assess progress we are making for, and with, the NiFi community. Feedback shows the user base is evolving. We see more Data Engineers, more Python developers, and more unstructured data use case. NiFi has a unique and differentiated capability to handle both unstructured and structured data at scale for both hands-on programmers as well as data analysts who appreciate the low-code experience. NiFi is an ideal solution to capture, transform, and deliver data to fuel Generative AI applications. The findings give us a strong and clear playbook of how to continue adding in the NiFi community at large. For Datavolo the feedback tells us we are making strong progress in empowering the 10X Data Engineer.
Stay tuned for a follow-up blog that unpacks Datavolo’s approach and how well it aligns to the survey findings.
If you have feedback, ideas, or simply want to learn more contact us here.